EMR on EKS 환경에서 spark driver 와 executor 가 같은 AZ 에 스케쥴링 되도록 하는 방법 (가용성까지 확보하면서)

![]()
EMR on EKS
EMR on EKS 란 EKS 에서 오픈소스 빅데이터 프레임워크를 실행 할 수 있는 아마존의 서비스를 의미한다. EKS 클러스터에서 Amazon EMR 기반 애플리케이션을 실행 할 수 있는데. AWS EMR 에 Spark Job 을 submit 하면 가상클러스터라고 불리는 EKS 환경에 Spark driver 와 Spark Executor 를 실행 할 수 있다.
Karpenter 와 함께 사용하면 그 편리함이 극대화 되는데, 무거운 Spark Job 이 수행되는 경우 Karpenter 에 의해 Node 가 자동으로 프로비저닝되고, 작업이 끝난 이후에는 해당 노드를 내리는 등의 작업을 자동화 할 수 있기 때문에 매우 비용 효율적이다.
현재 우리는 Airflow 와 함께 EMR on EKS 를 사용중인데. Airflow 의 EMROperator 클래스를 사용해서 필요한 Spark Job 을 주기적으로 실행하는 형태로 구성하였다. 현재 우리의 구성을 간략하게 그리면 아래와 같다.
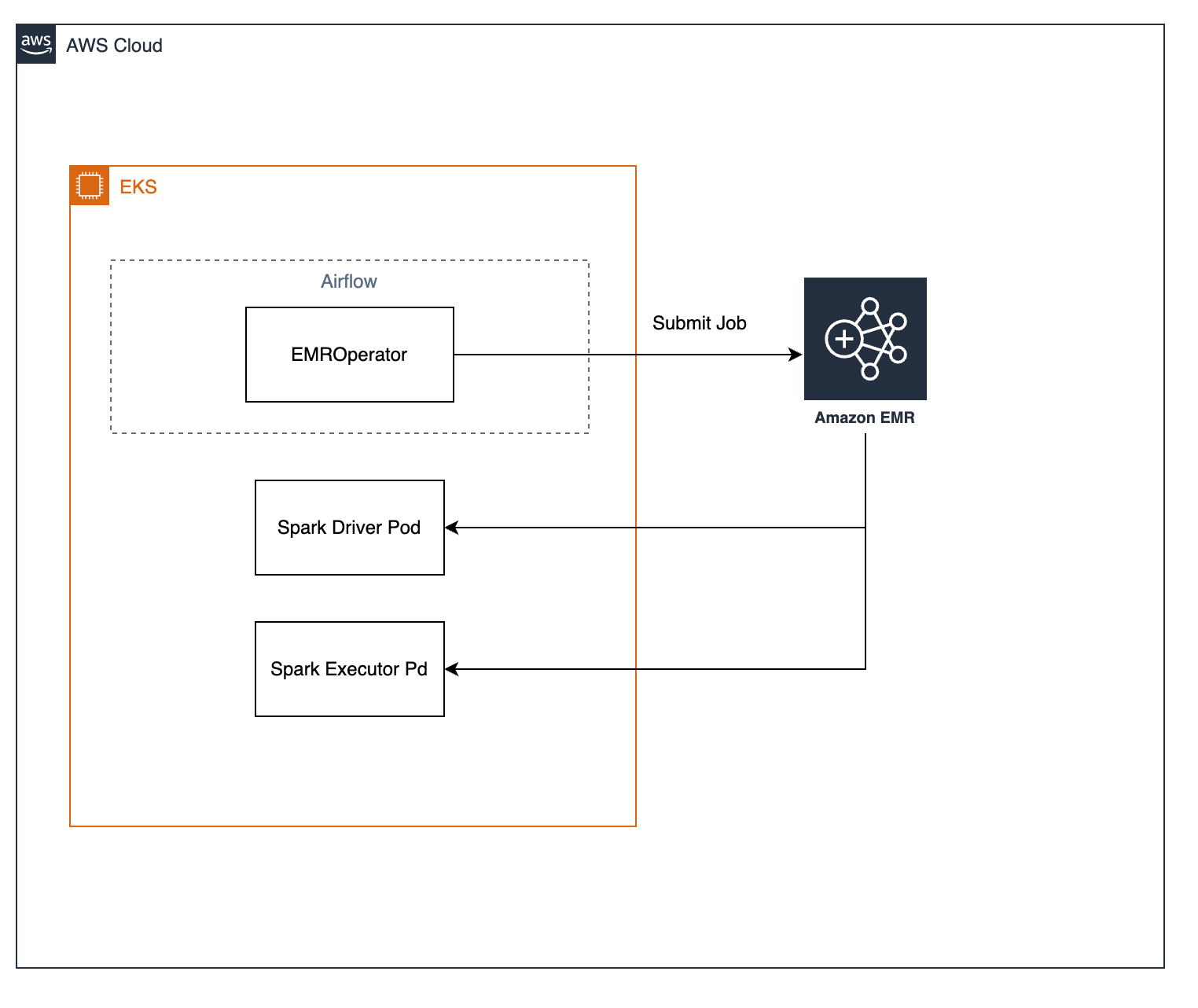
EMROperator 클래스를 통해 (정확히는 그것을 상속하여 별도로 구현한 Operator 를 사용중이다.) Spark Job context 와 함께 AWS EMR 에 job 을 submit 하면, AWS EMR 을 통해 EKS 클러스터 내에 Spark Driver Pod 와 Spark Executor Pod 가 생성되게 된다. (Job Submitter Pod 도 존재하는데 이 글에서는 해당 내용을 생략한다)
문제 상황
Spark Job 은 대부분 컴퓨팅 리소스(CPU, 메모리 둘다)를 많이 사용하는 작업이므로, Karpenter 를 통해 필요할때만 동적으로 컴퓨팅 리소스를 생성한다고 하더라도 EC2 비용이 매우 많이 발생하게 된다.
따라서 비용 효율성 개선을 위해 Spark Driver Pod 는 on-demand 머신에, Spark Executor Pod 는 spot 머신에 프로비저닝 하도록 podTemplate (https://spark.apache.org/docs/latest/running-on-kubernetes.html#pod-template)을 통해 설정하였다
위와 같은 PodTemplate 를 AWS EMR 에 job submit 할 때 제출하면, 우리가 지정한 properties (e.g spec.nodeSelector)를 갖고, 그 외 값들을 채워서 EKS 환경에 driver 와 executor 가 생성된다.
Spark Driver 의 경우 실패하면 모든 작업을 다시 시작해야 하지만 (executor 도 모두 종료), Spark Executor 의 경우 종료되더라도 전체 작업에 영향을 끼치지 않기 때문에 spot 인스턴스 환경에서 수행하는것이 훨씬 비용 효율적이였다.
문제는, 위와 같이 구성하였을 경우, 그리고 (당연히도) EKS 클러스터 환경의 노드가 여러 가용영역(AZ)에 존재하는 경우. AWS EMR 을 통해 생성되는 driver pod 와 executor pod 가 서로 다른 AZ 에 스케쥴링 되는 경우가 발생하고, 이러한 상황에서는 driver pod 와 executor pod 간의 통신이 모두 비용으로 발생하게 된다. (한국 리전 기준 $0.01 per GB)
https://aws.github.io/aws-emr-containers-best-practices/node-placement/docs/eks-node-placement/
아마존이 제공하는 AWS EMR 환경에 대한 Best Practice 문서를 보면 AWS EKS 기반의 쿠버네티스 클러스터의 워커노드가 여러 AZ 에 걸쳐서 있는 경우, Driver 와 Executor 가 서로 다른 AZ 에 프로비저닝 될 수 있고, 이런 경우 비용이 발생한다는 내용이 나와있다.
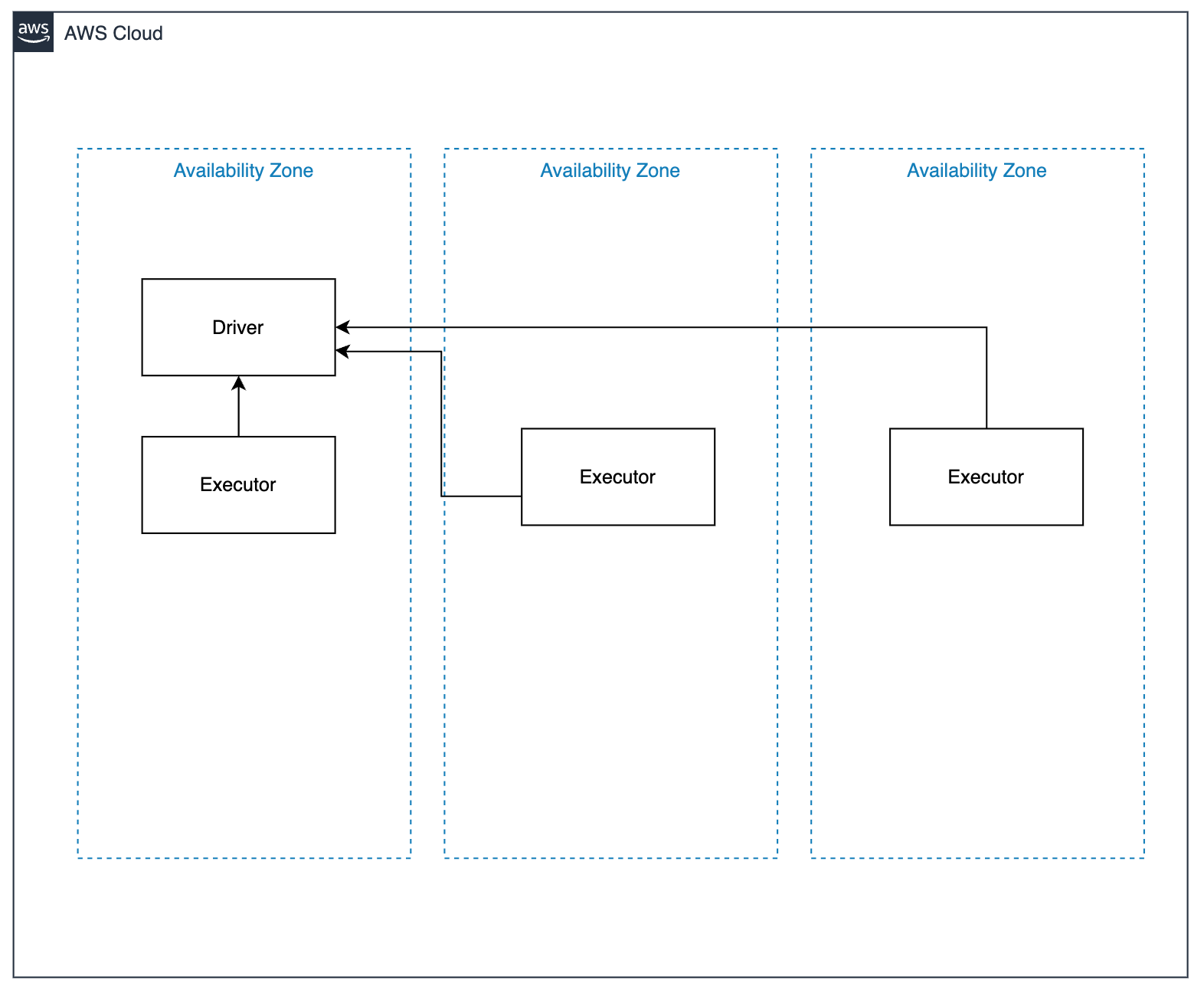
여기서 제공하는 솔루션은 spark job submit parameter 에 nodeSelector를 topology.kubernetes.io/zone 등을 설정하여 job 을 submit 하고 job submitter, driver, executor 등을 단일 AZ 에서 스케쥴링 되도록 하는 내용이다.
당연히 동작하긴 할것이다. 그렇지만 이 문서에서 나와있듯이 특정 AZ 를 하드코딩해서 사용하는 경우 해당 AZ 에 on-demand, spot 인스턴스가 부족한 경우에는 pending 상태에 빠질것이다. (karpenter 도 어떻게 해줄 수 없다. 실제 해당 AZ에 인스턴스가 부족한거니까)
그래서 오히려 job submitter, driver pod 는 아무 AZ 에 존재하는 노드에 프로비저닝 되도록 하고 (Kubernetes Scheduler 에게 전적으로 위임하고), executor pod 만 driver pod 와 동일한 AZ 에 있는 노드에 프로비저닝 되도록 하는것이 더 가용성 향상이 된다고 판단했다.
해결 방법
driver pod 가 떠있는 노드의 topology.kubernetes.io/zone 레이블을 갖는 노드에 executor pod 가 스케쥴링 되면 되는 상황이기때문에, 스케쥴러가 이런 상황을 처리 할 수 있는 inter-pod-affinity 를 사용하면 된다고 생각했다. (https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#inter-pod-affinity-and-anti-affinity)
inter-pod-affinity 란 해당 노드에서 이미 실행중인 파드의 레이블 을 기반으로 파드를 스케줄링 할 수 있는 노드를 제한 할 수 있는 기능이다.
driver pod 가 스케쥴링된 node 의 topology.kubernetes.io/zone 레이블의 값을 갖는 노드에 executor pod 를 프로비저닝 하고자 할 때 inter-pod-affinity 를 통해서 구현이 가능한 것이다.
inter-pod-affinity 는 상당한 처리량을 필요로 하는 작업이라 수백대 이상의 노드를 운영하는 클러스터에서는 사용이 권장되지 않는다. 파드가 스케쥴링되기 까지 (이 조건을 계산하느라) 오래 걸릴 수 있다고 한다.
위와 같이 구성하면 spark-app 이라는 driver pod 의 label 을 기반으로, 해당 파드가 떠있는 노드의 topology.kubernetes.io/zone 레이블의 값과 동일한 Node 에 스케쥴링 하도록 강제 할 수 있다. (topologyKey 참고)
이론적으로는 간단한 접근이였지만 현실적으로 아래와 같은 문제가 있었다.
- spark job 을 submit 하기 전에는 각 job 별로 고유한 job id 를 알 수 없다. 따라서 PodTemplate 은 spark job submit 하기전에 이미 있어야 하기 때문에 job id 기반의 레이블을 선택 할 수 없다.
- 그렇다면 각 Job 별로 (Airflow 환경에서는 DAG / Task) static 하게 app name 등을 지정하고, 그것을 통해서 레이블을 선택하도록 하면 되지 않을까? → 만약 같은 시간에 중복 실행되고있다면 문제가 발생 할 수 있다.
AWS EMR 에 job 을 submit 하기전에 driver 와 pod 에 대한 PodTemplate 을 전달해야 하는데, 즉 이 시점에서 driver 와 pod 를 고유하게 매칭시켜줄 수 있는 키/값을 고정해야만 우리가 하고자 했던 동작을 정확하게 구현 할 수 있다.
따라서 Airflow EMROperator 를 사용하는 우리 환경에, AWS EMR 에 job 을 submit 하기 이전에 해당 작업의 이름(e.g etl-foo-bar )과 timestamp 를 조합해서 affinity 를 사용하기 위한 label 과 value 를 고정하였다.
그리고 EMROperator 가 job 을 submit 하기 이전에 PodTemplate 을 동적으로 생성하여 S3 에 업로드하고, 그 S3 오브젝트의 경로를 AWS EMR 에 submit 할 때 같이 넘겨주는 방식으로 구현하였다.
spark.kubernetes.driver.label 형식으로 spark driver pod 의 레이블을 지정해줄 수 있고. 이것을 사전에 지정하고, PodTemplate 에는 지정된 label 의 value 를 inter-pod-affinity 에서 사용 할 수 있게 구현하였다. 동적으로 생성된 PodTemplate 은 S3 에 업로드하고, 그것에 대한 경로를 spark.kubernetes.executor.podTemplateFile , spark.kubernetes.driver.podTemplateFile 형태로 넘겨주어서 처리하였다.
이렇게 하여서 driver pod 에 대한 고유한 label key:value 를 job submit 하기 전에 핸들링 할 수 있고, 이것을 통해서 PodTemplate 을 생성하면 우리가 원하는 동작을 구현 할 수 있다.
이 케이스에서 label 의 key, value 는 어떤것을 사용해도 상관없다. 다만 value 는 동일한 작업에 대해서 여러번 submit 되거나 동시에 실행되는 상황이 발생해도 conflict 이 나지 않을 수 있게만 지정하면 된다.
쉽게 해결 할 수 없을까?
이렇게 특정 파드를 다양한 조건으로 스케쥴링 하는 방법은 Kubernetes 에서의 스케쥴러가 판단 할 수 있는 nodeSelector, affinity , topology spread constraints 등을 상황에 맞게 잘 조합해서 사용해야 한다.
이번 문제상황과 같은 경우에는 inter-pod-affinity 를 이용해서 쉽게 해결은 가능했지만. AWS EKS 뿐만 아니라 AWS EMR 이라는 중간 layer 가 들어가 있기 때문에 어느정도 우회법을 찾아서 해결을 해야 했다.
만약 spark on kuberentes 에서 podTemplate 에 대한 템플리팅 변수를 지원해주거나, AWS EMR 에서 그러한 기능을 지원해줬다면 지금과 같이 Airflow Operator (혹은 그외 다양한 여러분의 환경)레벨에서 구현할 필요가 없었을 내용이다.
예를들어
위와 같은 {JOB_ID} 등을 spark on kuberentes 혹은 AWS EMR 에서 처리를 해준다면
위와 같은 형태로 PodTemplate 만 간단하게 만들어서 구현 할 수 있었을 것이다.
하지만 안타깝게도 spark on kuberentes , AWS EMR 모두 이러한 기능은 제공되지 않기 때문에 환경에 맞게 적절한 우회법을 찾아서 구현해야 한다.
지금 상황의 경우도 mutatingWebhook 등을 커스텀하게 구현해서 affinity 부분을 동적으로 생성되게 구현한다면 더 우아하게 처리 될 수 있다.
Spark driver 와 executor Pod 가 생성 될 때 에는 downward API 를 사용 할 수 없기 때문에 AWS EMR 이 EKS 클러스터에 생성을 요청한 request 를 mutatingWebhook 에서 한번 가로채서, metadata 혹은 환경변수에 설정된 driver / executor 모두 동일하게 갖고있는 고유한 값(높은 카디널리티를 가지는 id 와 같은 값들이 두 파드 모두 설정되도록 생성된다)을 executor pod 의 labelSelector.matchLabels 에서 사용 할 수 있게 Pod Spec 을 조작하는 방식으로 구현도 가능하다.
결론
결론적으로 EMR on EKS 환경에서 동일 리전 / 다른 AZ 간 통신 비용을 줄이기 위해서는 driver pod 와 executor pod 가 같은 AZ 에서 실행되면 된다.
만약 정말 고가용성이 필요하지 않다면 자신의 EKS 환경에서 하나의 AZ 를 선택해서 driver / executor pod 의 nodeSelector 에 해당 AZ 를 하드코딩해서 사용하면 쉽게 해결이 가능하다.
하지만 만약 해당 AZ 가 어떠한 이유에서든 문제가 발생한다면 이런 상황에서 자동으로 처리가 되지 않기 때문에, driver pod (job submitter pod 포함) 해서 가능한 아무 AZ 에 스케쥴링 되도록 하고, executor 만 driver pod 가 스케쥴링된 노드의 AZ 와 동일하게 스케쥴링 되도록 하고 싶다면.
- 동적으로 PodTemplate 을 생성하는 전략
- mutatingWebhook 을 구현해서 처리하는 전략
두가지 방법이 있고, 이 글에서는 1번을 소개했다.