kube-apiserver 와 etcd 는 어떻게 통신하는가?
kube-apiserver 의 백엔드 스토리지이자, kubernetes 의 백엔드 스토리지인 etcd 에 대해서 kube-apiserver 가 어떻게 etcd 클러스터에 요청을 보내고 그 부하 분산을 어떻게 하는지 실제 kube-apiserver 및 etcd 클라이언트 분석을 토대로 정리한 글입니다. kube-apiserver 는 etcd v3 client 를 추상화한 별도의 계층을 사용해서 etcd 클러스터에 라운드로빈 형태로 트래픽을 분산해서 요청합니다. 이것은 gRPC 클라이언트 사이드 로드밸런싱과도 관련이 있는 내용입니다.
kube-apiserver
kube-apiserver 는 컨트롤플레인의 중추적인 역할을 담당하는 컴포넌트로, 모든 kubernetes client 요청(e.g kubectl) 을 처리하고, 그것의 결과를 etcd 로 부터 받아와서 전달하거나 etcd 에 데이터를 쓰는 역할을 담당합니다.
또한 kubelet , kube-controller-manager, kube-scheduler 또한 kube-apiserver 와 통신하며 클러스터의 상태를 감시하고 필요에 따라 리소스를 생성하거나, 업데이트하는 등의 작업을 수행합니다.
각 컴포넌트는 별도의 kubeconfig 파일을 통해 kube-apiserver 의 주소, 인증 정보를 들고있으며 보통 컨트롤 플레인에 설치된 kubelet , kube-controller-manager , kube-scheduler 등은 kube-apiserver 와 같이 설치되어있는 경우가 대부분이기 때문에 127.0.0.1:6443 등으로 로컬호스트를 바라보는 경우가 대부분입니다. (보통 kube-apiserver 도 떠있으니까.) kube-apiserver 가 로드밸런서와 연결되어있다면 로드밸런서 주소를 바라보게 설정 되어야 합니다.
etcd
kube-apiserver 는 결국 etcd 에 데이터를 조회하고, 데이터를 넣는 작업을 하게 됩니다. etcd가 쿠버네티스 클러스터의 백엔드 스토리지인 이유가 이것입니다.
etcd 는 분산 저장 key:value 스토리지/스토어로 클러스터링하여 사용하며 Raft 알고리즘에 의해서 클러스터 내에 어느 시점이든 오직 1개의 리더만이 존재하는 형태로 구성됩니다.
또한 etcd 에 어떤 요청이 들어왔을 때, 합의가 필요한 요청이 아닌 경우 (예를들어 읽기 조회) 는 요청이 들어온 etcd 노드가 리더든, 아니든 요청을 처리 할 수 있지만, 합의가 필요한 요청(쓰기)의 경우, 리더가 아닌경우 리더에게 전달하며, 리더는 합의 된 내용을 다시 팔로워들에게 전파하는 과정을 거치게 됩니다.
(참고 : FAQ )
kube-apiserver ↔︎ etcd
kube-apiserver 와 etcd 간 통신은 간단하게 설명해서 etcd가 공식 제공하는 go 언어로 짜여진 etcd v3 API 호환 클라이언트를 한단계 추상화한 것을 kube-apiserver 가 사용하고 있다. 라고 간단하게 정리 할 수 있습니다. 즉 etcd 클라이언트를 직접 호출하는 것이 아니라, 한단계 wrapping 되어서 추상화된 레이어를 사용해서 etcd 와 통신하고 있습니다.
따라서 우리가 정말 kube-apiserver 와 etcd 가 어떻게 통신하는지. 예를들어
- kube-apiserver 에 등록된
etcd-servers에 있는 모든 서버에게 읽기 / 쓰기 요청을 호출 할까? - 아니면
etcd-ervers중 리더를 찾아서 리더에게만 쓰기 요청을 호출하고, 읽기 요청은 일종의 라운드로빈 같은 로드밸런싱을 통해서 호출 할까? - 아니면 그런거 없이 그냥 아예 랜덤으로
etcd-servers중 하나에 요청하고 읽기 요청이면 리더가 아니더라도 잘 처리 되고 쓰기 요청이면etcd내에서 리더에게 알아서 다시 전달할까?
같은 의구심을 처리하기 위해서 kube-apiserver 와 etcd 클라이언트를 동시에 분석 할 필요가 있습니다.
더 나아가서 일반적인 경우 etcd 앞단에 로드밸런서를 두지 않는 이유가 무엇일지도 정리해나가면서 파악하는것이 이 글의 목표입니다.
그래서 무엇 무엇을 알아 봐야 할까?
위에서도 설명했지만
kube-apiserverkube-apiserver가etcd를 호출할 때 사용하는 추상화된 레이어- 추상화된 레이어 안에서 사용되는
etcd클라이언트 etcd클라이언트 자체
이렇게 네 가지 부분정도를 확인하면 실제로 kube-apisever 가 어떻게 etcd 와 상호작용 하는지 알 수 있을 것으로 예상됩니다.
동작
우선 근본적으로, etcd client 가 어떻게 동작하는지 알면 kube-apiserver 가 etcd 를 어떻게 추상화했든지는 알 필요 없이 동작을 이해 할 수 있습니다.
현재 etcd 3.4 버전 이상부터는 clientv3-grpc1.23 이라는 버전의 밸런서(클라이언트 사이드 로드밸런서라고 생각하면 됩니다)를 사용합니다.
etcd 는 gRPC 서버를 제공하고, 그것에 통신하기위한 gRPC 클라이언트는 클라이언트 사이드 LB(Balancer)를 사용 가능합니다.
동작은 아래와 같습니다.
- etcd 클라이언트는 etcd 클러스터 노드들에 대한 TCP 커넥션을 모두 들고 있습니다.
- 만약 etcd 멤버가 3이면 3개, 5이면 5개겠죠
- 그리고 모든 요청에 대해서 읽기/쓰기 상관 없이(정확히는 리더에게 전달해서 합의를 해야하는 요청이든, 아니든 상관 없이) 라운드 로빈 형태로 순차적으로 각 etcd 멤버들에 요청을 보냅니다.
- 이 때 만약 읽기 요청이라면 요청받은 etcd 노드가 그대로 응답을 던집니다.
- 이 때 쓰기 요청이라면, 그리고 요청받은 etcd 노드가 리더라면 그대로 리더가 합의하에 처리합니다.
- 이 때 쓰기 요청이고, 그리고 요청받은 etcd 노드가 팔로워라면 리더에게 전달합니다.
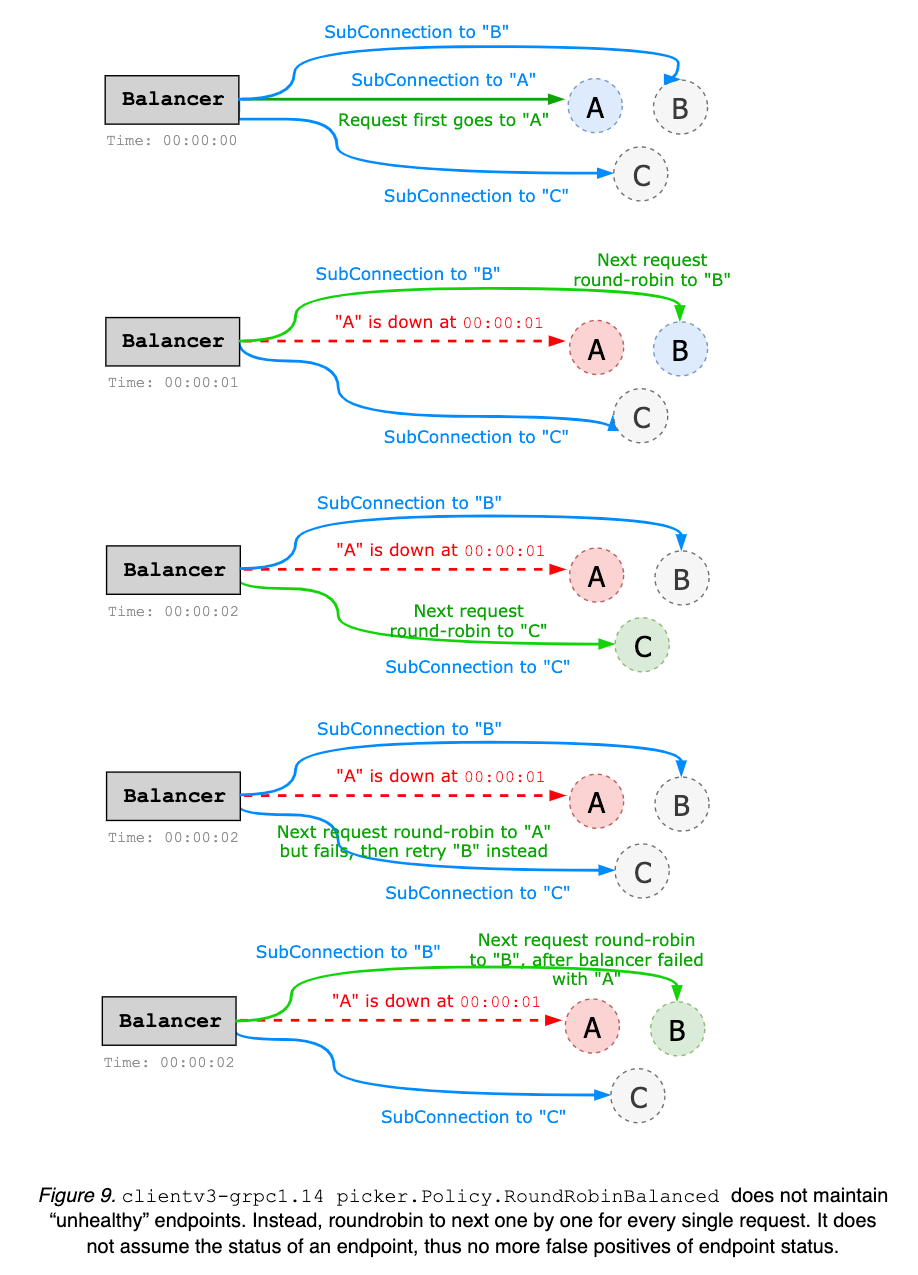
clientv3-grpc1.23 의 Balancer 구조https://github.com/etcd-io/etcd/blob/main/client/v3/internal/resolver/resolver.go
etcd 클라이언트의 resolver 라는 코드가 이러한 로드밸런싱에 관련된 부분을 처리하는데 기본적인 로드밸런싱 정책은 round_robin 입니다. 그리고 이 로드밸런싱은 etcd 가 별도 구현하는것이 아닌 gRPC 리졸버 라고 부르는 코드쪽에서 구현된 것이고. 그것과 관련한 문서는(gRPC Load Balancing ) 여기서 볼 수 있습니다.
clientv3-grpc1.23 밸런서부터는 이제 모든 etcd 노드에 대해서 TCP 커넥션을 유지하면서 처리한다고 하고, 그러한 구조를 통해서 앞으로 round_robin 뿐만 아니라 power of two, pick leader 같은 로드밸런싱 정책 구현도 쉽게 가능할것이라고 문서에서 설명합니다. (이건 주의할것이, 아직 구현되었다는것은 아닙니다. 현재는 여전히 round_robin 만 사용 가능)
실제 동작 검증
192.168.203.2 : node1 / etcd1 / control plane
192.168.203.3 : node2 / etcd2 / control plane
192.168.203.4 : node3 / etcd3
192.168.203.5 : node4 / etcd4
192.168.203.6 : node5 / etcd5
위와 같이 Kubernetes 클러스터를 생성하고(kubespray). 테스트해봅니다. (컨트롤플레인 노드만 두고 워커노드는 그냥 두지 않았습니다.)
또한 etcd 는 모두 systemd 서비스로 (static pod 가 아닌) 프로비저닝 하였습니다.
여기서 보고자 하는 부분은 kube-apiserver 가 각 etcd 노드에 별다른 가중치 없이 돌아가며 요청을 보내는지 확인하는것이 목적입니다. 가능하면 etcd put 요청시 리더가 아닌 etcd 노드에 요청이 들어갔을 때 리더에 전달하는 부분까지 확인하고싶었지만 테스트의 어려움이 있어(저보다 잘 하시는 분이 테스트 해보시고 공유좀!) 이정도 선에서만 테스트 해보겠습니다.
#!/bin/bash
# kube-apiserver 포트 찾기
PORTS=$(netstat -ntep | grep kube-api | awk '{print $4}' | cut -d':' -f2 | sort | uniq | paste -sd "," -)
if [ -z "$PORTS" ]; then
echo "kube-apiserver 포트를 찾을 수 없습니다."
exit 1
fi
# tcpdump 필터 생성
FILTER="src host 192.168.203.2 and dst port 2379 and ("
for PORT in $(echo $PORTS | tr "," "\n"); do
FILTER+="src port $PORT or "
done
FILTER=${FILTER%or }
FILTER+=")"
# tcpdump 실행
echo "실행하는 tcpdump 명령어: sudo tcpdump -i any -nn '$FILTER'"
sudo tcpdump -i any -nn "$FILTER"위와 같은 형태의 쉘 스크립트를 작성하고 수행해봅니다. 위 쉘 스크립트는 kube-apiserver 가 etcd 와 연결되면서(2379번포트) 동적으로 할당받은 TCP 포트들을 찾아내서, node1 에서 출발해서 다른 모든 호스트의 2379 번으로 넘어가는 트래픽을 캡쳐하는 스크립트입니다.

kube-apiserver 에서 etcd 로의 요청은 라운드로빈 형태로 돌아가면서 요청이 들어가는 것을 볼 수 있다.위 캡쳐를 잘 확인해보면 192.168.203.2 에서 실행중인 kube-apiserver 에서 etcd 모든 노드 (192.168.203.[2:6]) 으로 호출을 돌아가면서 하는 것을 볼 수 있습니다.
만약 모든 요청이 etcd 의 리더에 들어가는게 아니였어? 생각 할 수 도 있는데. 리더는 아래와 같았습니다.
export ETCDCTL_API=3
HOST_1=192.168.203.2
HOST_2=192.168.203.3
HOST_3=192.168.203.4
HOST_4=192.168.203.5
HOST_5=192.168.203.6
ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379,$HOST_4:2379,$HOST_5:2379
/usr/local/bin/etcdctl --endpoints=$ENDPOINTS \
--cacert=/etc/ssl/etcd/ssl/ca.pem \
--cert=/etc/ssl/etcd/ssl/admin-node1.pem \
--key=/etc/ssl/etcd/ssl/admin-node1-key.pem \
--write-out=table \
endpoint status
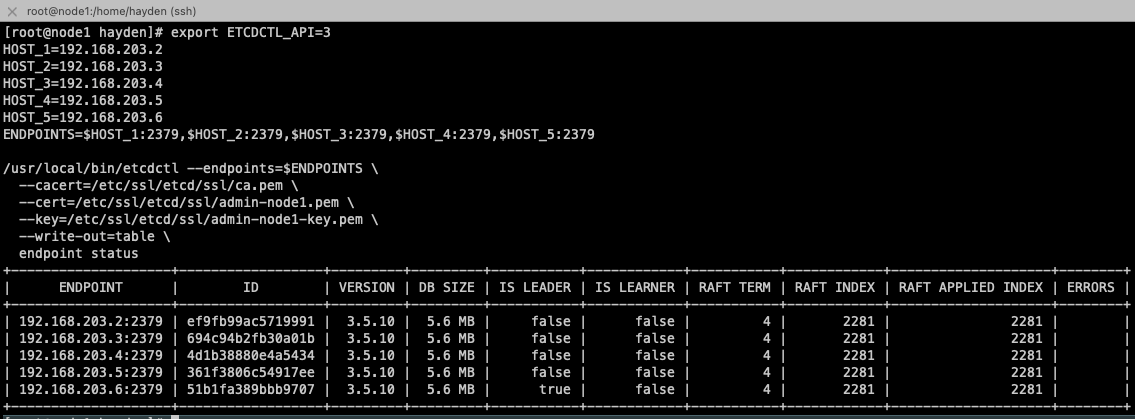
이를 통해서 kube-apiserver → etcd 통신은 리더에게만 전달되거나, 모든 etcd 에 동시에 전달되는것이 아니라 round_robin 형태로 로드밸런싱 되어서 골고루 분산되어서 요청이 전달된다는것을 확인 할 수 있었습니다.
번외
위에서는 kube-apiserver 가 wrapping 해서 사용중인 etcd v3 client 의 기본적인 클라이언트 사이드 로드밸런싱 정책이 round_robin 이기 때문에 kube-apsierver 가 바라보는 etcd 서버들에게 돌아가면서 요청을 전달합니다. (https://github.com/etcd-io/etcd/blob/e7b3bb6ccac840770f108ef9a0f013fa51b83256/client/v3/internal/resolver/resolver.go#L43 )
이러한 로드밸런싱 정책은 etcd 또한 grpc-go 에서 구현된 것을 사용하고 있고. 관련한 문서는 (https://github.com/grpc/grpc-go/blob/master/examples/features/load_balancing/README.md ) 여기서 찾아 볼 수 있습니다. Default 옵션은 pick_first 인데, etcd v3 client 는 기본적으로 round_robin 으로 하도록 위쪽 permalink 처럼 확인이 가능합니다.
여기서 pick_first 정책을 etcd v3 client 에서 정말 사용이 가능할지 테스트를 해보고자 아래와 같이 테스트를 해보았습니다.
 kimsehwan96
kimsehwan96자세한 내용은 위 git repo 에 README.md 로 작성해두었습니다.
Wrapping up
kube-apiserver 는 각 etcd 멤버들에게 골고루 부하를 분산하면서 GET , PUT , WATCH 등의 요청을 하게 됩니다. 만약 etcd 에서 합의가 필요한 요청인 PUT 요청을 리더가 받았다면 그대로 처리 후 전파, 팔로워가 받았다면 우선 리더에게 전달후 처리 등의 동작을 하게 되고, 그 외 합의가 필요하지 않은 요청은 받은 etcd 노드가 바로 처리해서 전달하게 됩니다.
따라서 특정 etcd 멤버에 부하가 과도하게 걸리거나 하는 걱정은 이미 etcd 클라이언트의 클라이언트 사이드 LB 가 처리해주고 있기 때문에 크게 걱정할 부분은 아닙니다.
재미있는점은 etcd 공식 문서중 클라이언트 디자인 부분에서 향후 Balencer 쪽에서 power of two , pick leader 등의 LB 정책 (현재는 round_robin 만 제공)을 확장할 생각이 있는 것 같기도 합니다.
(power of two 는 랜덤하게 2개의 백엔드 인스턴스를 골라서 그 중 한개에 트래픽을 보내는 LB 전략. https://www.haproxy.com/blog/power-of-two-load-balancing)
(pick leader 는 아마도 ETCD 리더에게만 트래픽을 보내는 전략으로 구현 예정인 듯)
결론적으로 kube-apiserver 앞단에 로드밸런서(HAProxy / Nginx 같은 소프트웨어 LB, 혹은 L4 Switch 같은 물리 LB 등)를 두는것과 다르게 etcd 는 클라이언트 사이드 LB를 통해 추가적인 네트워크 홉을 줄이면서 gRPC 의 성능 향상(HTTP2) 부분을 그대로 가져갈 수 있는 디자인을 채택한것 같습니다.
이 부분을 deep dive 하면서 자연스럽게 gRPC 에서의 LB 에 대한 의구심이나 정리할점도 많다고 느꼈는데 (https://grpc.io/blog/grpc-load-balancing/#load-balancing-options) 이 부분은 추후에 정리해서 자세히 포스팅 하도록 하겠습니다.