K8s 오퍼레이터
쿠버네티스 오퍼레이터가 무엇인지에 대해서 알아봅니다. 우선 오퍼레이터라는 말 자체는 소프트웨어 디자인 패턴에서 나오는 하나의 용어로 이해를 하면 됩니다. 오퍼레이터 패턴이란 운영 노하우, 도메인 지식등을 갖고있는 운영자의 역할을 소프트웨어에 새긴 개념으로 볼 수 있습니다. 쿠버네티스의 오퍼레이터도 그런 관점에서 동일한 컨셉을 갖고 있습니다.

오퍼레이터 디자인 패턴
오퍼레이터는 Introducing Operators: Putting Operational Knowledge into Software CoreOS 블로그에서 공개된 디자인 패턴으로 운영자의 역할을 소프트웨어에 새긴 개념입니다. SRE / DevOps 엔지니어는 애플리케이션을 운영하는 엔지니어로서 운영 노하우, 도메인 지식등이 수반되어야 소프트웨어 개발/운영이 가능한데. 이러한 애플리케이션 운용에 있어서 가용성이 유지되도록 할 때 엔지니어가 수동으로 작업하는 부분이 꽤나 있습니다.
CNCF에서 소개한 위 자료에서는 상태를 수동적으로 관리해주어야 하는 한계를 극복하기 위해 고안된 오퍼레이터 패턴의 역할과 기능에 대해 자세하게 설명되어있습니다.
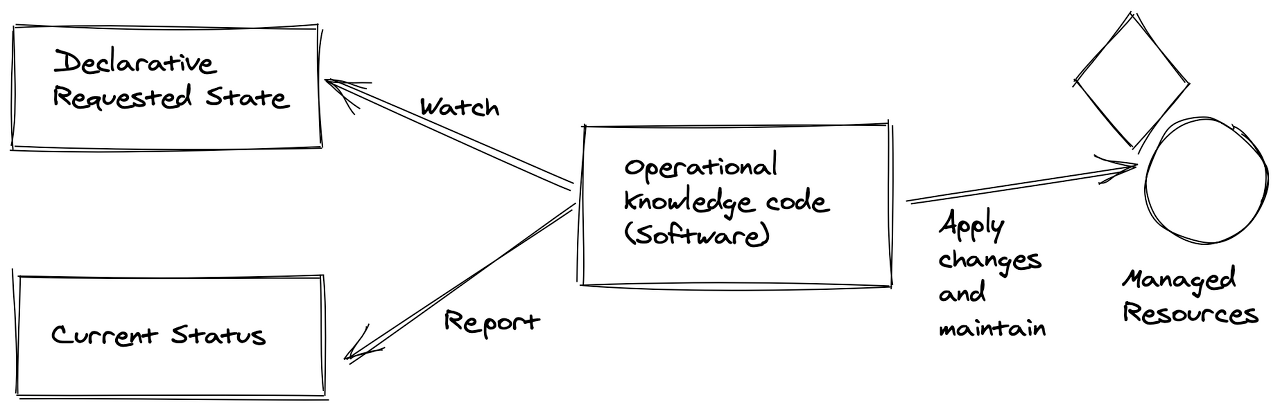
이 오퍼레이터 패턴은 세 가지의 구성요소로 구성되는데
- 관리하려는 애플리케이션 또는 인프라
- 사용자가 선언적 방식으로 애플리케이션의 원하는 상태로 지정할 수 있게 해주는 도메인 특화 언어
- 지속적으로 실행되는 컨트롤러
- 상태를 읽고 인식
- 자동화된 방식으로 애플리케이션에 대한 작업을 실행
- 선언적 방식으로 애플리케이션의 상태를 보고
쿠버네티스의 오퍼레이터 구성요소
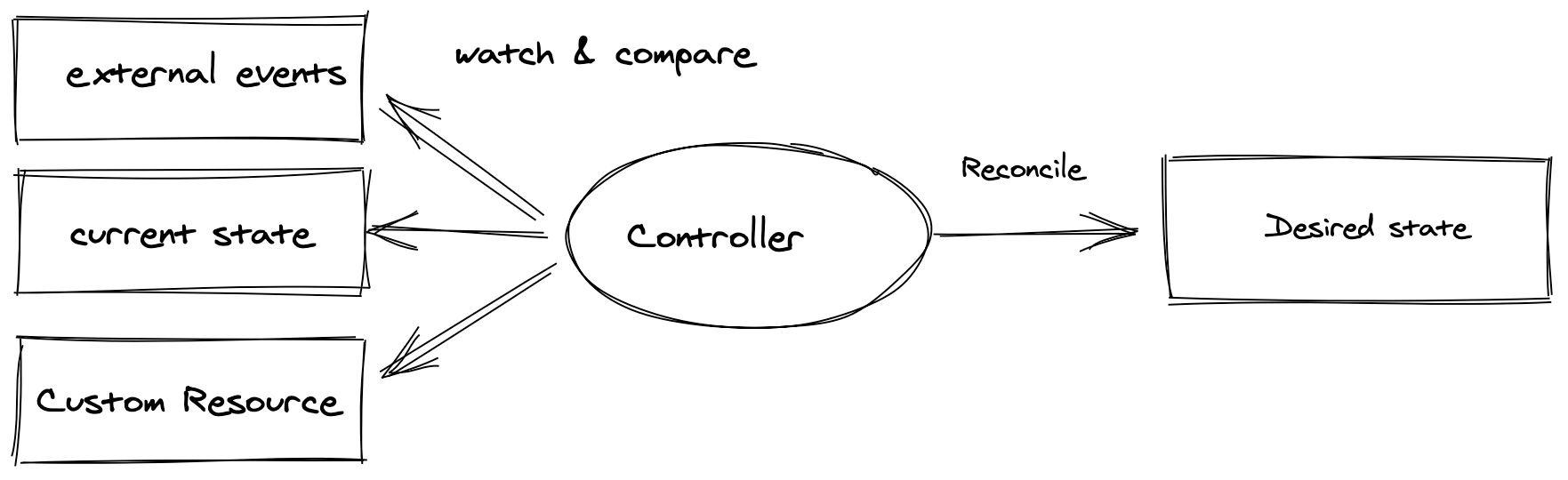
- 쿠버네티스 컨트롤러
- Custom Resource / Custom Resource Definition
- 컨트롤 루프
컨트롤러는 하나 이상의 여러 오브젝트를 감시 할 수 있으며, 이 객체는 Deployment, Service 같은 쿠버네티스의 기본 요소일 수도 있고, 가상머신, 데이터베이스와 같은 클러스터 외부에 있는 객체일수도 있습니다. 컨트롤러는 감시중인 객체가 정의된 방식으로 원하는 상태(Desired State)로 전환되도록 보장하는 컨트롤 루프를 사용해서 원하는 상태를 현재 상태와 지속적으로 비교합니다. Desired state는 하나 이상의 Kubernetes Custom Resource Definition에 캡슐화 되고, 컨트롤러에는 객체를 Desired state로 만드는 운영 지식이 포함되어있습니다.
쿠버네티스 컨트롤러
쿠버네티스 컨트롤러는 특정 리소스 유형으로 표현되는 Desired state로 실제(현재)상태가 일치되도록 관리합니다. 예를들자면 Deployment 컨트롤러는 하나의 파드가 삭제되거나 실패 할 때 원하는 양의 파드 복제본이 실행되고 새 파드가 가동되도록 관리합니다.
Custom Resource / Custom Resource Definition
Custom Resource는 Kubernetes API 를 확장하는 방식입니다. Kubernetes API 에서 리소스는 특정 종류의 API 오브젝트 모음을 저장하는 엔드포인트라고 할 수 있습니다.
예를들어서 Kuberentes 에 내장된 Pod 리소스에는 Pod 오브젝트의 모음이 포함되어있습니다.
Custom Resource Definition은 고유한 객체 종류를 정의하고, API 서버가 전체 라이프 사이클을 처리 할 수 있도록 합니다. (파드의 라이프사이클을 API 서버가 관리하듯)
이것을 통해 사용자가 정의한 리소스를 만들어서 Desired State(원하는 상태)를 선언 할 수 있고, Operator 패턴과 함께 사용해서 Desired State 로 유지하도록 하는것이 보통의 유즈케이스입니다.
컨트롤 루프
컨트롤 루프는 쿠버네티스 컨트롤러 내에서 운영 지식을 기반으로 사용자 정의 리소스, 혹은 기존 K8s 리소스, 혹은 이벤트등을 감지해서 Desired State 로 만드는 반복되는 루프라고 할 수 있습니다.
정리
오퍼레이터는 운영 지식을 담아 운영을 자동화하는 소프트웨어의 디자인 패턴이라고 볼 수 있고. 파드를 재배치하거나, 원하는 상태로 되도록 조정하고, Custom Resource Definition & Custom Resource 를 통해 도메인지식/운영지식을 담아서 쿠버네티스 API를 확장하고, Custom Controller (CRD / CR 을 감시하고, 동작하도록 하기 위한 구성요소)는 그것들을 보고 실제 쿠버네티스 오브젝트를 배치하거나, 각종 조작등을하게 됩니다.
다만 Keel 같은 쿠버네티스 오퍼레이터는 CRD / CR 및 Custom Controller를 따로 두지 않고 primitive 쿠버네티스 오브젝트(Deployment / Stateful Set / Daemon Set)등을 관리해주는 역할을 하게 됩니다.
그러니까 CRD/CR , Custom Controller 는 필수 사항은 아니지만, 대부분의 오퍼레이터(Datadog Operator, ECK operator, Istiod그외 다양한 오퍼레이터들)들은 CRD/CR 을 통해 Kubenernets API 를 확장하고, CR 을 사용해 선언한 Deisred State 로 유지하도록 동작하게 됩니다.
간단하게 예를 들자면 Datadog 오퍼레이터를 사용하지 않을 경우 Helm을 통해 혹은 직접 Deployment, ConfigMap, Service Object, Service Account 등을(primitive k8s object)를 생성해서 구성해야겠지만, Datadog 오퍼레이터를 사용하면 Datadog 에서 제공하는 CR 을 통해 간단하게 구성을 할 수 있게 됩니다.
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
global:
credentials:
apiSecret:
secretName: datadog-secret
keyName: api-key
appSecret:
secretName: datadog-secret
keyName: app-key
features:
apm:
enabled: true
logCollection:
enabled: true
위와 같이 CR 을 통해 추상화된 리소스를 사용 할 수 있다.
개인적인 의견으로는, 설정이 복잡한 애플리케이션의 경우 대부분 Operator 도 제공해주고 있고 해당 Operator 가 업데이트가 잘 되고 있다면 사용하는데 크게 문제가 없다고 생각이 들긴 합니다. 그렇지만 그럼에도 Operator 를 사용하지 않고 구성 할 수 있는 경우에는 Operator 를 사용하지 않고 구성하는것이 장애포인트를 한단계 낮추는 작업이 된다고도 생각합니다.
그럼에도 Operator 패턴을 거의 무조건 써야한다고 생각이 들 때가 있는데, Istiod 처럼 Istio 의 확장 API (Istio 에서는 Gateway, VirtualSerice, DestionationRule 등등)를 수도 없이 많이 써야 할 경우와, primitive k8s 오브젝트로 커버 할 수 없는 정보를 저장하고, 그 정보를 토대로 오퍼레이터가 동작해야하는 경우가 그 경우라고 생각합니다.(물론 ConfigMap, Secrets 같은것들로 정보 자체를 넘겨 줄 수야 있겠지만, 가독성 측면에서 CR이 더 낫지 않을까요?)
예시로 Istio 를 들긴 했지만 해당 시스템에서, 해당 시스템 컨텍스트(추상적으로 이야기했지만..)안에서 돌아가야하는 리소스가 매우매우 많은 경우에는 오히려 primitive k8s 오브젝트를 쓰는것보다 나을거라고 생각합니다. (ArgoCD 도 이런 케이스라고 생각됩니다.)
잘못 된 정보를 수정해주시거나 피드백을 주실 것이 있으면 댓글은 언제든 환영입니다.