Raft 알고리즘 알아보기
Raft 알고리즘 논문 : https://raft.github.io/raft.pdf
더 자세한 버전의 논문 : https://web.stanford.edu/~ouster/cgi-bin/papers/OngaroPhD.pdf
Raft는 복제된 로그들을 관리하기 위한 합의 알고리즘 입니다. Paxos 와 비슷한 결과를 낼 수 있으며, Paxos 만큼이나 효율적인 알고리즘입니다. 하지만 Paxos 보다는 더 이해하기 쉬운 알고리즘이기도 합니다. Raft 의 이해도를 높이기 위해서, Raft 는 리더 선출, 로그 복제, 안전과 같은 합의 알고리즘의 핵심 요소를 분리하고 고려해야하는 상태의 수를 줄이기 위해 더 높은 수준의 일관성을 적용합니다.
Raft 는 다른 합의 알고리즘 (Oki, Liskov’s Viewstamped Replication..)과 비슷하지만, 몇가지 주목할만한 기능들이 있습니다.
- Strong Leader : Raft 는 다른 합의 알고리즘에 비해 더 강력한 형태의 리더십을 사용합니다. 예를들자면 로그 항목은 오직 leader 에서 다른 서버로만 전달됩니다. 이를 통해 복제된 로그 관리를 간단하게 하며, Raft 를 더 이해하기 쉬운 알고리즘으로 만들어줍니다.
- Leader election : Raft는 리더를 선출하기 위해 랜덤화된 타이머를 사용합니다. 다른 합의 알고리즘에서 필요한 heaatbeat 에 아주 작은 부분만 추가한것이고, 복잡성을 줄이고 신속하게 리더를 선출 할 수 있게 합니다.
- Membership changes : 클러스터의 서버 집합(set)을 변경하는 작동 방식은 새로운 방식의
joint consensus방식을 사용합니다. 두 개의 서로 다른 구성이 전환중이더라도 클러스터가 계속 정상 동작 할 수 있습니다.
Replicated state machine
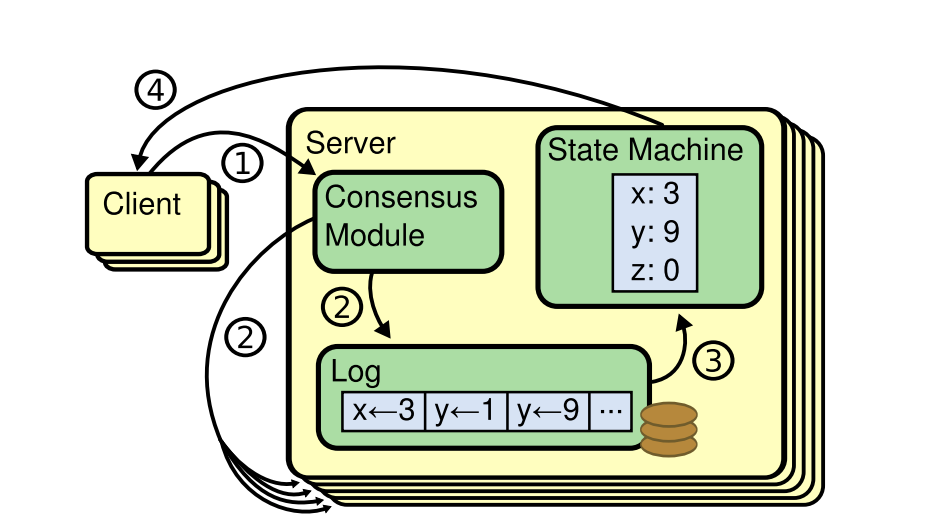
합의 알고리즘은 Replicated state machine 개념으로부터 출발했습니다. 이러한 접근법을 통해 여러 서버에 존재하는 상태머신은 명확하게 같은 상태를 복제하고, 일부 서버가 중단되더라도 정상적으로 동작하도록 합니다.
Replicated state machine 는 분산 시스템에서의 다양한 내결함성 문제를 해결하기위해 사용됩니다.
Replicated state machine 은 일반적으로 복제된 로그를 기반으로 구현됩니다.(위 사진 참조)
각 서버는 상태 머신이 순서태로 처리한 일련의 command 를 포함한 복제된 로그를 갖고 있고. 각 복제된 로그는 같은 command 를 같은 순서로 갖고 있어서 각 상태머신은 같은 command 들을 같은 순서로 처리합니다. 각 상태머신은 결정론적이므로 같은 상태를 계산하고, 같은 순서의 결과들을 반환합니다.
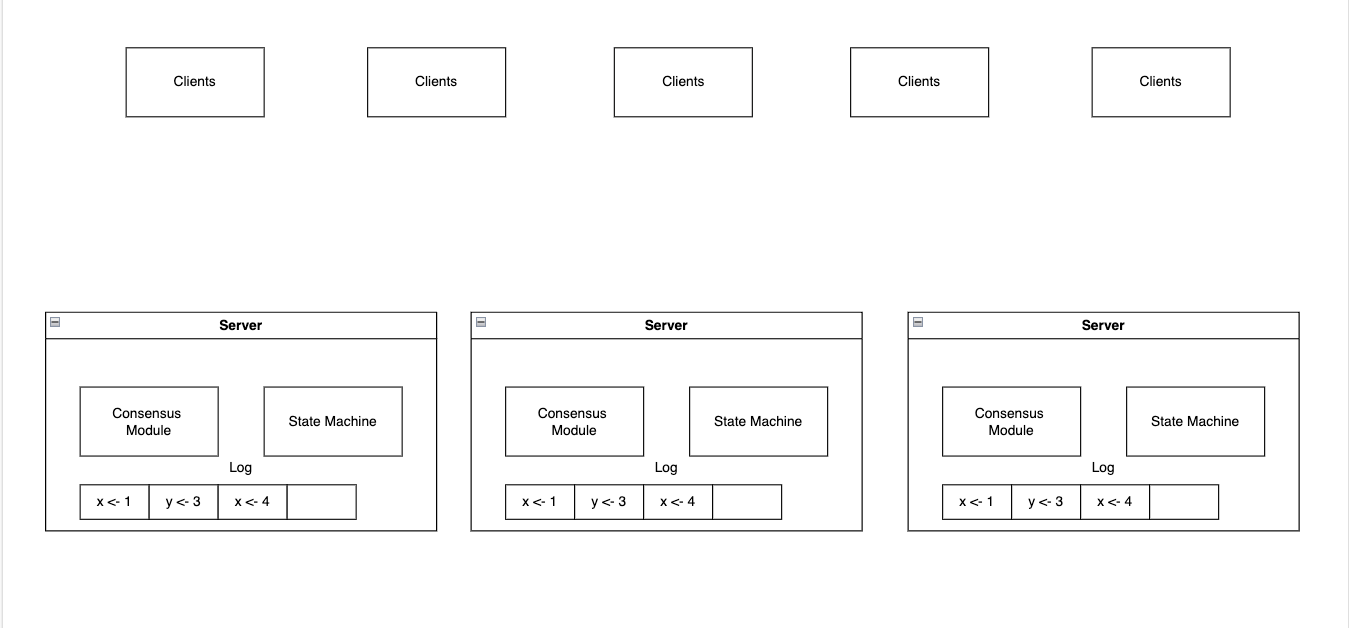
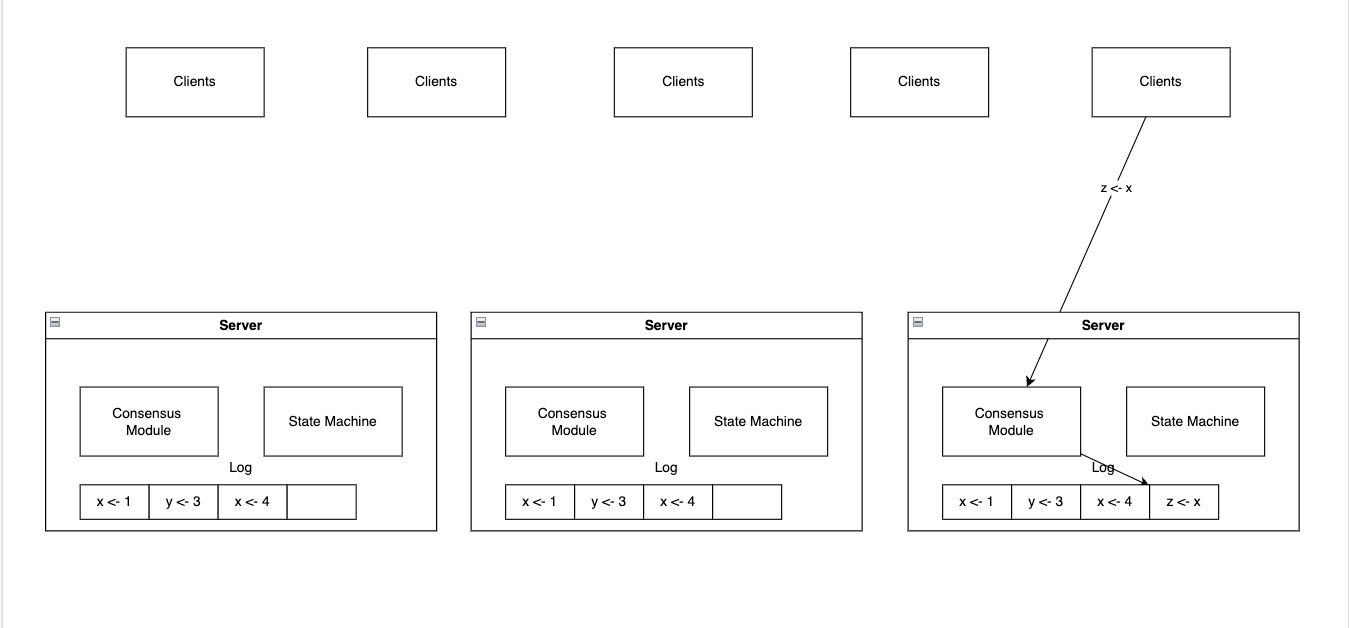
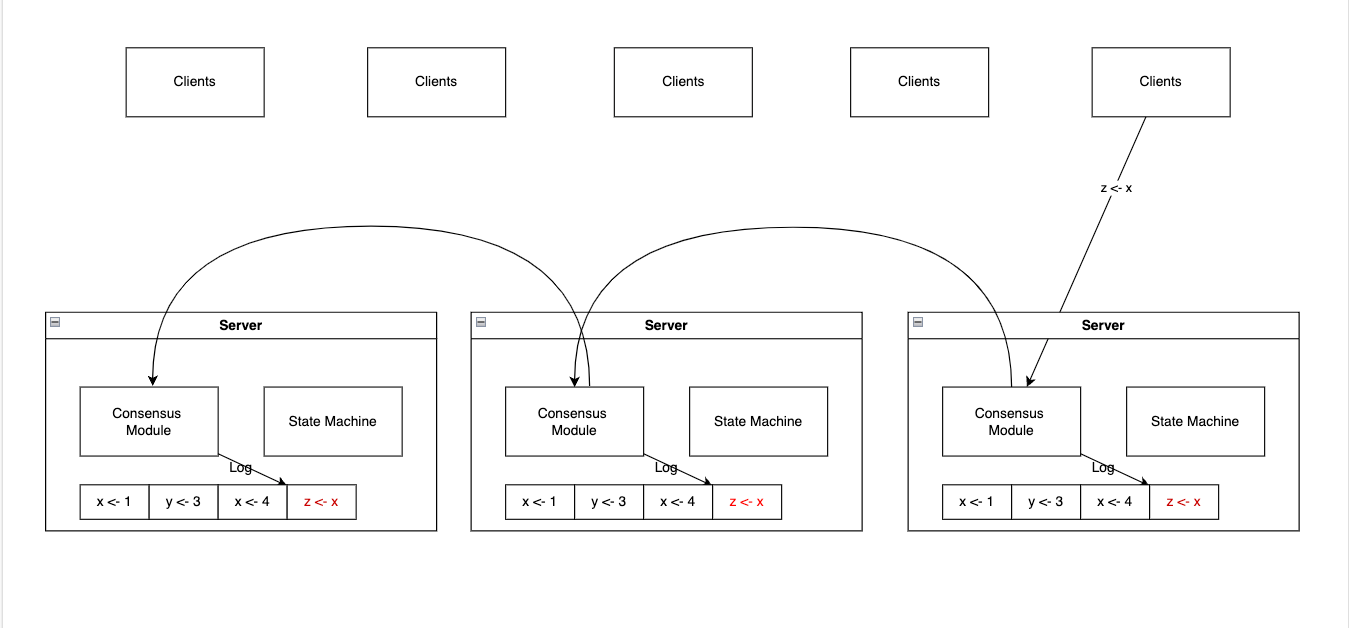
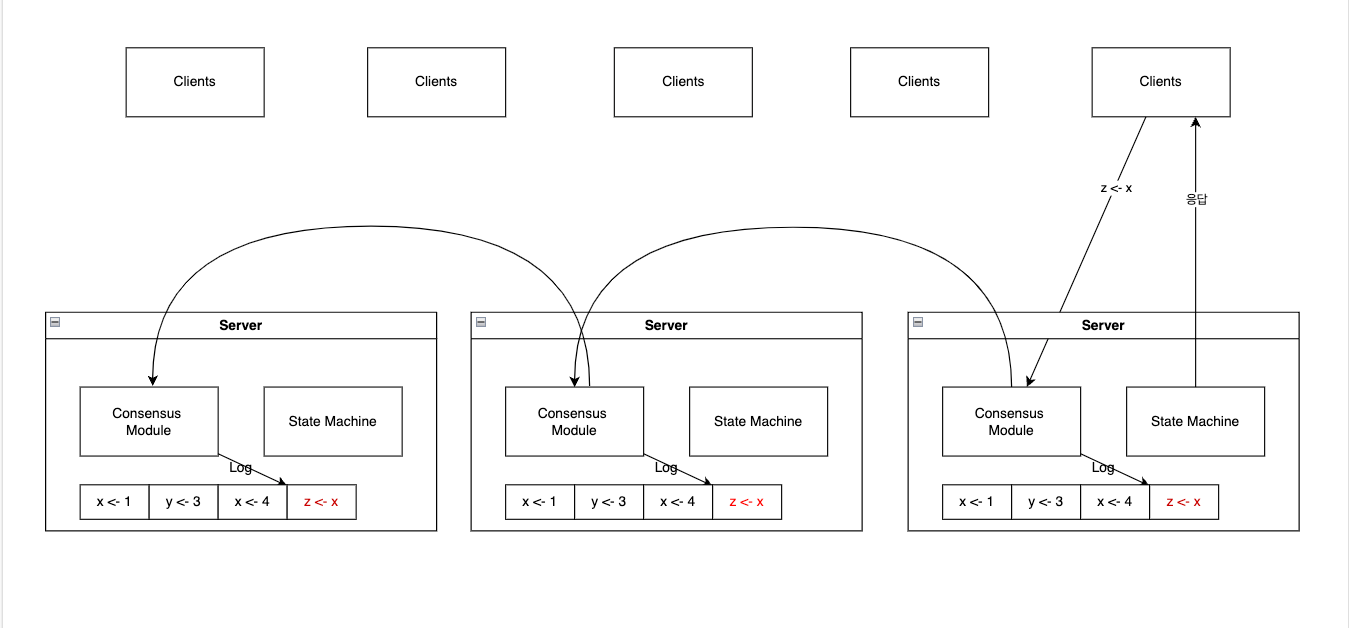
복제된 로그를 일관성 있게 유지하는것이 합의 알고리즘이 하는 일입니다. 서버에 있는 합의 모듈(Consensus Module) 클라이언트로부터 command를 수신하고, 그것을 log 에 추가합니다. 그리고 합의 모듈은 이룹 서버가 문제가 생기더라도 모든 로그가 같은 요청을 같은 순서로 저장하도록 보장하기 위해서 다른 서버에 있는 합의모듈과 통신합니다.
command들이 정상적으로 복제되었다면(로그로 잘 쌓였다면) 모든 서버의 상태머신은 로그를 순서대로 처리하게 되고, 모든 서버의 요청에대한 결과는 동일하게 됩니다. 결과적으로 서버들은 하나의 매우 안정적인 상태머신처럼 보이게 됩니다. (어떤 서버에 요청을 해도 동일한 응답을 받을 수 있으니까, 게다가 그 서버들중 몇개가 죽더라도 문제가 없으니까)
실제 시스템에 사용하기위한 합의 알고리즘은 아래과 같은 속성을 갖습니다.
- 네트워크 딜레이, 네트워크 패킷 유실 과 같은 모든 비잔틴 장애 조건이 아닌 상황에서 결함이 없어야(safety 해야)합니다.
- 서버의 대부분이 작동하고 클라이언트와 서로 통신 할 수 있는 한 기능적으로 완벽히 동작해야합니다. 따라서, 일반적인 5대의 서버로 구성된 클러스터는 어떤 서버가 장애가 발생하든 2개의 서버까지 장애는 견뎌 낼 수 있습니다. 서버는 중지됨으로써 장애가 발생하는것으로 가정되고, 장애가 발생한 서버들은 추후에 안정적인 스토리지에서 상태를 복구하고, 클러스터에 다시 join 할 수 있어야 합니다.
- 로그의 일관성을 유지하기 위해 타이밍에 의존하지 않습니다. 고장난 클럭과 심각한 메시지의 지연은 심각한 상황에서 가용성 문제를 발생시킬 수 있습니다.
- 일반적으로 클러스터의 과반수가 단일 RPC 호출에 응답하면 command를 완료 할 수 있습니다. 소수의 느린 서버가 클러스터 전체 성능에 영향을 미치지 않아야 합니다.
이해하기 쉽게 설계
Raft 를 설계할 때 몇가지 목표가 있었습니다.
하나는 개발자들이 설계를 하는데 시간을 확실히 줄일 수 있도록, 시스템을 만들기 위한 완벽하고 실질적으로 사용 가능한 기초(뼈대)를 제공하는 것이였고, 다른 하나는 일반적인 운영 상황에서는 효율적으로 동작하면서, 모든 조건에서 안전하게 동작하고, 특정한 조건의 운영 상황에서도 사용 가능하도록 하는것이 목표였습니다.
하지만 가장 큰 목표는 (그리고 제일 어려웠던) 바로 이해하기 쉽게 만들기였습니다.
많은 청중들이 알고리즘을 편안하게 이해할 수 있게 해야 했고, 시스템을 구축하려는 사람들이 실제 구현에서 불가피하지만 필요한 확장을 할 수 있도록, 이 알고리즘에 대한 직관을 얻을 수 있게 해야 했습니다.
결론적으로 Raft 알고리즘을 설계하면서 아래와 같은 두가지 기법을 사용하게 되었는데.
- Problem decomposition (문제 분해) : Raft 의 설계에서 복잡한 문제를 더 작고 독립적으로 설명하고 해결 할 수 있는 부분들로 나누어 접근하는 방식입니다. 예를들어서 리더 선출, 로그 복제, 안정성 검증, 멤버십 변경등과 같은 부분을 별도의 구성요소(문제)로 분해해서 설명합니다.
- Smplify the state space (상태 공간 단순화): 시스템이 가질 수 있는 가능한 상태의 수를 줄임으로써 시스템을 더 일관성 있게 만들고 비결정성(nondeterminism)을 가능한한 제거합니다.
예를들어서 로그는 비어있는 데이터를 저장할 수 없고 Raft는 로그들이 서로 일치하지 않도록 하는 작업/방법을 제한합니다.
하지만 가끔은 비결정성이 이해도를 더 높이기도 하는데. 예를들자면 무작위화(Randomization)가 그랬습니다.
무작위화는 비결정성을 오히려 도입하기는 하지만, 모든 가능한 선택을 비슷한 방식으로 처리하기 때문에 오히려 상태공간을 줄일 수 있었는데.(아무거나 선택해도 상관 없다 라는 관점) Raft 의 리더 선출 알고리즘에서의 무작위화가 상태공간을 줄일 수 있는 케이스였습니다.

멤버십 변경과 로그 압축을 제외한 Raft 합의 알고리즘의 요약 번역
모든 서버에서 유지되는 영속적 상태 (RPC 응답 이전에 안정적인 저장공간에 업데이트되는 상태)
- currentTerm: 서버가 본 최신 임기 (0으로 초기화하고 단조롭게 증가)
- votedFor: 현재 임기에 투표한 후보 (null이면 투표하지 않음)
- log[]: 로그 항목들; 각 항목은 상태 머신 명령과 그것을 리더로부터 받은 임기를 포함 (첫 인덱스는 1)
모든 서버에서의 휘발성 상태
- commitIndex: 알려진 로그 항목 중 커밋된 것으로 알려진 최신 인덱스 (0으로 초기화하고 단조롭게 증가)
- lastApplied: 상태 머신에 적용된 로그의 최신 인덱스 (0으로 초기화하고 단조롭게 증가)
선거 후에 재초기화되는 휘발성 상태
- nextIndex[]: 다음 로그 항목의 인덱스를 각 서버에게 보낼 때 (리더로 초기화하고 각 서버에 대해 1로 설정)
- matchIndex[]: 각 서버에서 복제된 가장 높은 로그 항목의 인덱스 (0으로 초기화하고 단조롭게 증가)
RequestVote RPC
리더 선출에 대한 표를 모으기 위해서 후보자가 호출
인자
- term: 후보자의 임기
- candidateId: 투표를 요청하는 후보자의 아이디
- lastLogIndex: 후보자의 마지막 로그 인덱스
- lastLogTerm: 후보자의 마지막 로그 항목의 임기
응답
- term: 후보자가 자신의 현재 임기를 업데이트하기 위한 현재 임기
- voteGranted: 후보자에게 투표가 되었으면 true
수신하는쪽의 구현
- 현재 임기가 인자의 임기보다 크거나 이미 투표한 경우 거짓으로 응답
- 로그가 최소한 수신자의 로그만큼 최신이라면 true로 투표
AppendEntries RPC
리더가 로그 항목들을 복제하기 위해서 호출 + 하트비트로 사용됨
인자
- term: 리더의 임기
- prevLogIndex: 이전 로그 항목의 인덱스
- prevLogTerm: 이전 로그 항목의 임기
- entries[]: 복제할 로그 항목들 (하트비트에는 비어있을 수 있음)
- leaderCommit: 리더의 commitIndex
응답
- term: 수신자가 자신의 현재 임기를 업데이트하기 위한 현재 임기
- success: 수신자가 prevLogIndex와 prevLogTerm을 포함하는 항목을 가지고 있다면 true
수신쪽 구현
- 인자의 임기보다 현재의 임기가 크다면 false 로 응답. (이걸 호출한 리더는 임기가 최신이 아니라 리더의 자격이 없으니까)
- 만약 로그가 prevLogIndex에서 prevLogTerm과 일치하는 항목을 포함하고 있지 않다면 거짓을 반환합니다
- 만약 기존 항목이 새 항목과 충돌한다면 (같은 인덱스이지만 다른 임기), 기존 항목과 그 뒤의 모든 항목을 삭제합니다
- 로그에 아직 없는 새 항목들을 추가합니다
- 만약 leaderCommit이 commitIndex보다 크다면, commitIndex를 min(leaderCommit, 마지막 새 항목의 인덱스)로 설정합니다.
Rules for Servers모든 서버
- 만약 commitIndex > lastApplied이면: lastApplied를 증가시키고, 상태 머신에 log[lastApplied]를 적용합니다
- 만약 RPC 요청 또는 응답이 currentTerm보다 큰 T라는 임기를 포함하고 있다면: currentTerm을 T로 설정하고, 팔로워 상태로 전환합니다
팔로워
- 후보자와 리더로부터 온 RPC에 응답합니다.
- 만약 선거를 위한 타임아웃이 리더로부터 AppendEntries RPC(Heatbeat)를 받지 않은 상태로 지나가거나, 후보에게 투표하지 않은 상태라면 후보 상태로 전환합니다.
후보자(Candidate)
- 후보자로 전환하면, 선거를 시작합니다:
- currentTerm을 증가시킵니다.
- 자기 자신에게 투표합니다.
- 선거 타이머를 재설정합니다.
- 다른 모든 서버에게 RequestVote RPC를 보냅니다.
- 만약 서버의 과반수로부터 표를 받으면: 리더가 됩니다.
- 만약 새로운 리더로부터 AppendEntries RPC를 받으면: 팔로워 상태로 전환합니다.
- 만약 선거 타임아웃이 지나면: 새로운 선거를 시작합니다.
리더
- 선거에서 승리한 후: 각 서버에게 초기 빈 AppendEntries RPC (하트비트)를 보냅니다; 유휴 시간 동안 이를 반복하여 선거 타임아웃을 방지합니다
- 만약 클라이언트로부터 명령을 받았다면: 로컬 로그에 항목을 추가하고, 상태 머신에 항목이 적용된 후에 응답합니다.
- 만약 마지막 로그 인덱스 > 팔로워의 nextIndex라면: nextIndex에서 시작하는 로그 항목과 함께 AppendEntries RPC를 보냅니다.
- 성공적이면: 팔로워에 대한 nextIndex와 matchIndex를 업데이트합니다.
- 만약 로그 불일치로 인해 AppendEntries가 실패한다면: nextIndex를 감소시키고 다시 시도합니다.
- 만약 N이라는 수가 있어서 N > commitIndex이고, 과반수의 matchIndex[i] >= N이고, log[N].term == currentTerm이라면: commitIndex를 N으로 설정합니다.
Raft는 복제된 로그를 관리하기 위한 알고리즘입니다. 우선 Raft는 하나의 단일 리더를 선출하고, 리더에게 복제된 로그들을 관리할 책임을 주는것으로부터 합의 알고리즘 구현을 시작합니다.
리더는 클라이언트로부터의 로그 생성을 허용하고, 다른 서버들에게 로그를 복제해줍니다, 그리고 상태 머신에 언제 로그 생성을 적용해야 안전한지도 전달합니다.
리더는 복제된 로그를 관리하는것을 간단하게 만듭니다. 예를들어 리더는 다른 서버들과 의견을 주고받을 필요 없이 새로운 로그 생성을 언제, 어디에 해야할지 정합니다.
따라서 데이터는 리더로부터 다른 서버로 간단하게 흐르게 됩니다. 리더가 실패하거나 다른 서버들과의 연결이 끊어 질 수 있는데 이 경우에는 새로운 리더가 선출됩니다.
put 과 같은 데이터를 새로 생성하는 동작을 팔로워 etcd 멤버가 받더라도 리더에게 전달하는 이유가 바로 이것입니다.이러한 접근법을 통해 Raft 는 합의 문제를 아래와같은 세개의 독립적인 하위 문제로 분리합니다.
- 리더 선출 : 새로운 리더는 기존에 존재하는 리더가 실패하는 경우에만 선출합니다.
- 로그 복제 : 리더만 클라이언트가 요청하는 로그 생성을 허용하고 전체 클러스터에 거쳐 로그를 복제합니다. 또한 다른 로그들이 자신의 로그와 일치하도록 강제합니다.
- 안정성 : Raft에 있어서 핵심적인 안정성은 바로 상태 머신이라는 점인데, 만약 어떤 서버가 특정 로그 항목을 자신의 상태머신에 적용했다면, 다른 서버는 동일한 로그 인덱스에 대해서 다른 command(명령/항목)을 적용 할 수 없습니다. 뒷 부분에서 어떻게 이것을 보장하는지 설명합니다.

- 선출 안정성 :
term을 임기라고 앞으로 이야기하겠습니다. 단일 임기동안 오직 하나의 리더만이 선출됩니다. - 리더는 Append only : 리더는 절대로 로그항목을 덮어쓰거나 삭제하지 않습니다. 오직 생성만 합니다.
- 로그 일치 : 만약 두 로그가 동일한 인덱스와 항목을 갖고 있다면, 그 로그들은 주어진 인덱스를 통해 모든 항목에 있어서 동일합니다.
- 리더 Completeness : 어떤 로그 항목이 특정 임기(어떤 리더가 존재할 때) 커밋되었다면, 그 항목은 더 높은 번호의 임기(term)을 가진 모든 리더들의 로그에 존재합니다.
- 상태 머신 안정성 : 만약 서버가 로그 항목을 특정 인덱스에서 자신의 상태머신에 적용했다면, 다른 서버는 그 인덱스에 대해서 다른 로그 항목을 적용 할 수 없습니다. (그러니까 애초에 데이터에 대한 conflict이 나지 않는것)
Raft 의 근간
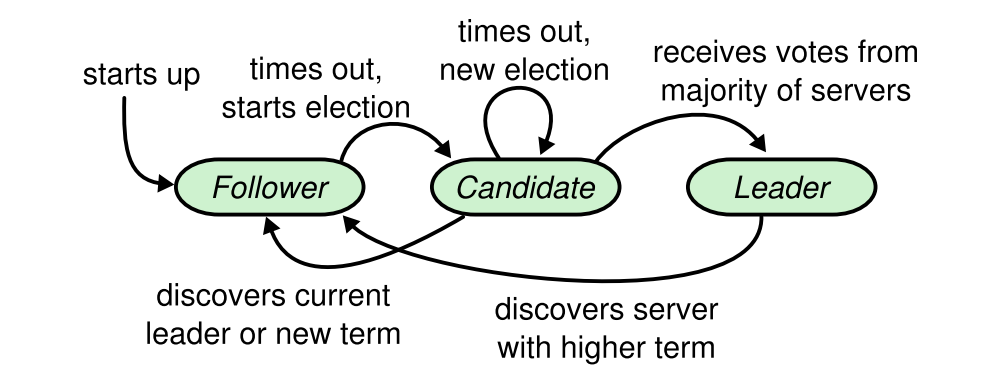
Raft 클러스터에는 여러 서버가 포함되어있고, 일반적으로 5대를 사용하고, 이런 경우에는 2대의 서버 고장을 버틸 수 있습니다. 어떤 상황속에서도 각 서버는 세가지 상태 중 하나인데, 각 상태는 리더, 팔로워, 혹은 후보자(candidate)입니다.
정상 동작중에는 오직 하나의 리더가 있고, 다른 모든 서버는 팔로워입니다. 팔로워는 수동적이라서 단순히 리더와 후보로 부터 온 요청에만 응답합니다. 리더는 모든 클라이언트의 요청을 처리합니다. (논문에는 이렇게 적혀있지만, etcd 의 경우는 그렇지 않기 때문에 더 확인 해 볼 필요가 있음)
세번째 상태인 후보자는 새로운 리더를 뽑기 위해서 사용됩니다. 아래 그림은 이러한 리더, 팔로워, 후보 상태 변화를 간략하게 보여줍니다. 뒤에서 리더 선출에 대해서 자세히 다룹니다.
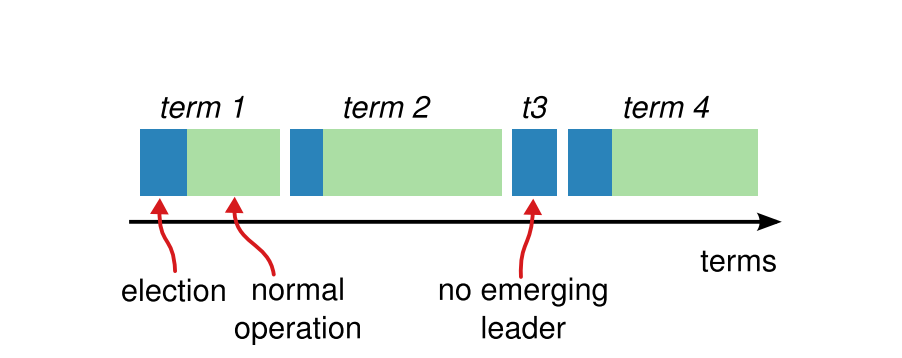
아래 그림에서 보여지는 것 처럼 임의의 길이의 임기로 시간을 나눕니다. 이 임기는 연속정인 정수로 번호가 매겨집니다. 각 임기는 선거로 시작되며, 하나 이상의 후보가 리더가 위해서 서로 경쟁합니다.
한 후보가 리더 선출 선거에서 과반수 이상 득표하면, 그 임기동안 리더로서 역할을 합니다. 어떤 상황에서는 선거가 실패하는데, 이런 경우 리더 없이 해당 임기를 끝내고, 새로운 임기(새로운 리더 선출 선거 시작과 함께)가 시작됩니다.
이렇게 해서 Raft 는 한 임기에 오직 하나의 리더만 존재할 수 있도록 보장합니다.
각 서버는 단순하게 증가하는 정수로된 임기 번호를 저장합니다. 임기는 서버들이 통신 할 때 마다 서로 정보를 교환하며, 만약 한 서버의 임기가 다른 서버의 임기보다 작다면 작은 임기를 더 큰 값으로 업데이트 합니다.
만약 후보자나 리더가 자신의 임기가 구식이라는걸 발견하면 그 즉시 팔로워 상태로 되돌아갑니다. 또한 구식 임기 번호를 가진 요청을 받으면 그 요청을 거부합니다.
Raft 서버들은 원격 프로시저 호출(RPC)를 사용해 통신하고. 기본적인 합의 알고리즘은 오직 두종류의 RPC만이 필요한데. RequestVote RPC 와 AppendEntries RPC가 그것입니다.
RequestVoteRPC 는 리더 선출 선거 기간 중에 후보자들에 의해서 발생되고, AppendEntries RPC는 리더들이 로그 항목을 복제하고 하트비트 형태를 제공하기 위해 시작됩니다.
InstallSnapshot RPC 라는 추가적인 확장 RPC도 존재하는데 이는 뒤에서 다루겠습니다.
서버들이 응답을 못받는 경우 RPC를 재시도하고, 성능을 위해 병렬로 요청합니다.
리더 선출
Raft는 리더 선출을 발생시키기 위해서 heatbeat 메커니즘을 사용합니다. 서버들이 최초에 시작되었을 때, 팔로워 상태로 시작합니다.
서버는 유효한 RPC를 리더나 후보자로부터 수신하기 전까지 팔로워 상태로 남아있습니다.
리더는 주기적으로 heatbeat(정확히는 로그 항목을 포함하지 않는 AppendEntries RPC를 보냅니다)를 팔로워들이 그들의 우선순위를 유지하도록 보냅니다.
만약 팔로워가 election timeout 이 끝나기 전까지 아무 정보를 받지 못한다면, 살아있는 리더가 없다고 판단하고 새로운 리더를 선출하기 위한 선거를 시작합니다.
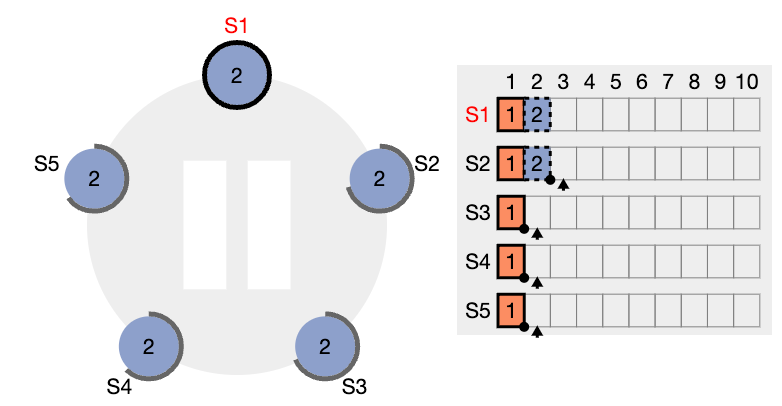
선거를 시작하기 위해서 팔로워는 자신의 현재 임기(term) 숫자를 증가시키고(1 증가시킵니다) 자신을 후보자 상태로 바꿉니다. 그리고 해당 후보자는 자기 자신에게 투표하고, RequestVote RPC 를 병렬적으로 다른 모든 서버들에 보냅니다.
그리고 후보자는 아래 세개의 일중 하나가 발생하기 전까지 자신의 상태를 유지합니다.
- 선거에서 승리(정족수 이상 득표)
- 다른 서버가 리더가 되는 경우
- 리더 선출에서 아무도 승리하지 못하고 특정 시간이 지난 경우
만약 같은 임기(term)에서 전체 클러스터에 대해서 정족수 이상을 득표하면 후보자는 리더 선출 선거에서 승리하게 됩니다. 모든 서버들은 같은 임기 내에서 선착순으로 오직 하나의 후보자에게만 투표합니다.
그리고 정족수 이상 득표해야 리더 선출 선거에서 승리하는 규칙은 적어도 하나의 후보자만 특정 임기 내에서 승리 할 수 있음을 보장하기도 합니다.
후보자가 선거에서 승리하는 경우 후보자는 리더가 됩니다. 그리고 모든 서버들에게 자신들의 우선순위를 설정하도록(팔로워 상태로 유지하라고), 그리고 새로운 선거를 시작하지 않도록 heartbeat 메시지를 남은 모든 서버에게 보냅니다.
투표를 기다리는 동안, 후보자는 AppendEntries RPC 를 다른 서버로부터 해당 서버가 리더라고 이야기하는 정보를 받을수 있습니다. 만약 RPC에 들어있는 해당 리더의 임기(term)가 자신의 term 보다 적어도 같거나, 크다면 후보자는 해당 리더를 정상적인 리더라고 인지하고 팔로워 상태로 변환됩니다.
만약 RPC 안에 있는 임기(term)이 후보자의 현재 임기(term)보다 작다면, 후보자는 그 RPC 를 거부하고 계속해서 후보자 상태를 유지합니다.
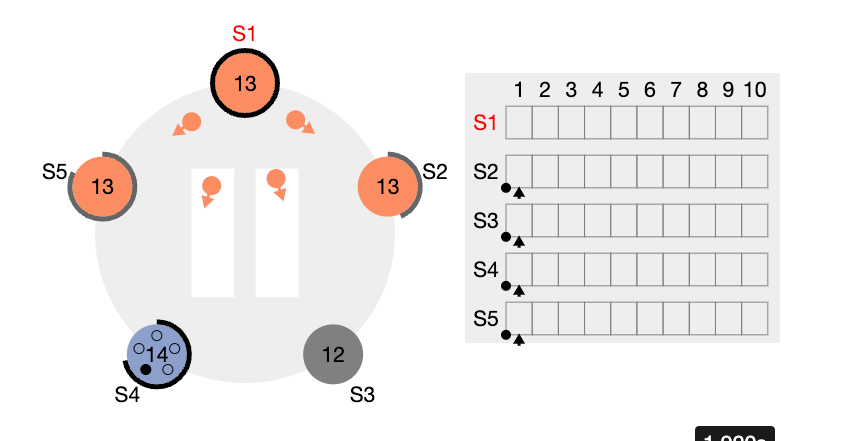
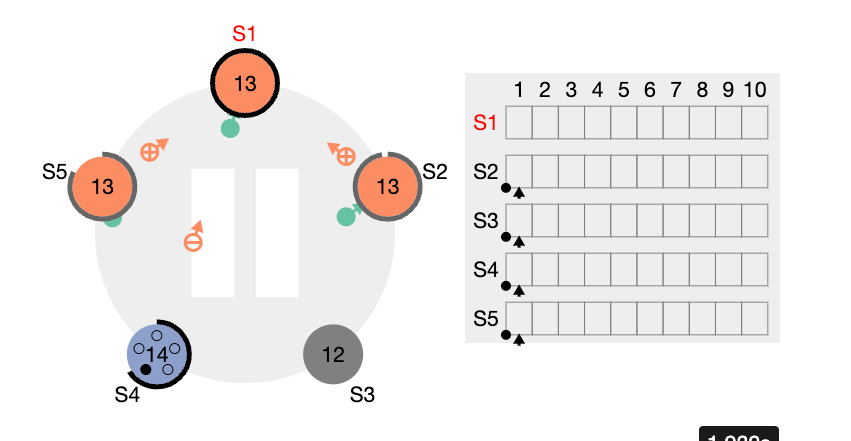
- 표시는, AppendEntries 를 reject 한다는 의미이다. 반면 S5 와 S2는 S1 이 보낸 term 의 자신과 같거나 큰 조건에 부합하기 때문에 accept 한다. 이 와중에 S4 의 RequestVoteRPC가 S1, S2, S5에 전달되고 여기에는 term 정보가 들어있다. S1 리더를 포함한 S2, S5 팔로워들은 RequestVoteRPC 에 담겨있는 term 값이 자신이 갖고있는 값보다 크기 때문에 이제 term 값을 14로 설정하고, S4 에게 투표를 하게된다. 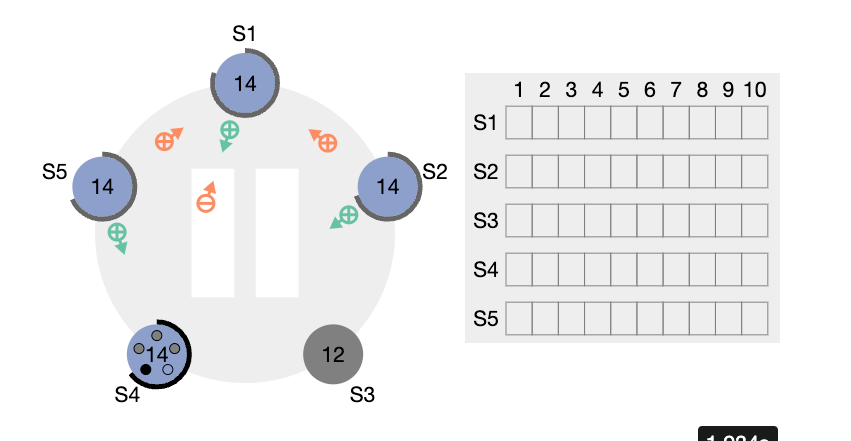
term 값이 13이였을 때의 정보가 담겨있기 때문에 별다른 처리를 하지 않는다.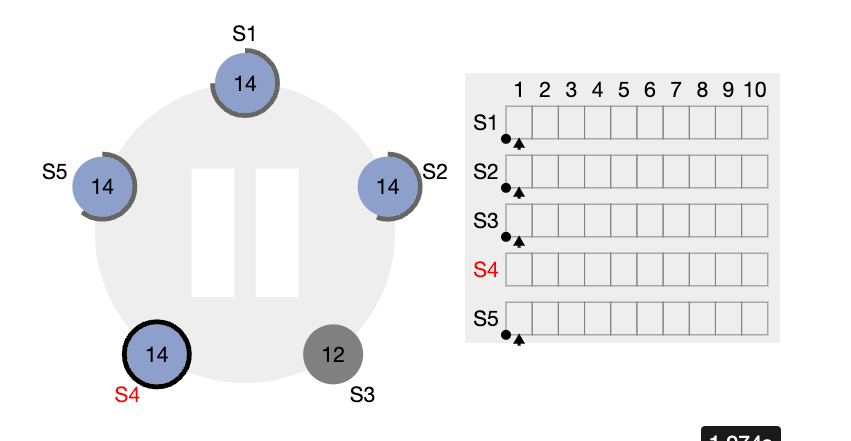
세번째 가능한 결과는, 후보자가 선거에서 이기지도, 지지도 않는 상황입니다. 만약 많은 팔로워들이 동시에 후보자가 된다면 어떤 후보자도 정족수 이상 득표를 할 수 없을겁니다.
이런 상황이 발생하면 각 후보자는 timeout 상태가 되고, 현재 임기 값을 1 늘리고 난 뒤 새로운 선거를 시작하고, RequestVote RPC 요청을 보냅니다. 어쨌든 추가적인 조치 없이는 이런 상황이 계속해서 발생 할 수도 있습니다. (만약 모든 서버의 타임아웃 설정이 동일하다면 ..)
Raft는 랜덤화된 election timeout 을 통해 이런 표가 분산되는 상황을 거의 없애고, 그런 일이 발생하더라도 빠르게 해결하도록 하였습니다. 이런 득표 분산상황을 막기위해서 election timeout은 고정된 범위의 시간대 안에서 랜덤하게 결정됩니다. (예를들어 150 ~ 300ms).
이런 조치는 대부분의 상황에서 오직 하나의 서버만 타임아웃 상태가 되도록 할 수 있고. 타임아웃 상태가 된 서버가 빠르게 리더가 되고 다른 서버가 timeout이 되기전에 heartbeat을 보낼 수 있게 합니다.
이와 동일한 메커니즘이 득표 분산을 막기 위해서 사용됩니다. 모든 후보자들은 선거가 시작되는 시점에서 랜덤화된 election timeout 을 설정하고 재시작하고, 다음 선거를 시작하기 전에 해당하는 timeout 까지 경과를 지켜봅니다.
로그 복제
리더가 한번 선출되고 나면, 리더는 클라이언트의 요청을 처리하기 시작합니다. 각 클라이언트 요청은 모든 복제된 상태머신에서 처리되어야 하는 command 를 포함하고 있습니다. (논문에서는 command로 지칭하지만, 단적으로 etcd를 생각한다면 저장할 데이터라고 생각해도 무방합니다.)
리더는 새로운 항목으로 해당 command 를 append 하고, AppendEntries RPC를 각 모든 서버에 병렬적으로 요청해서 해당 항목을 복제하도록 합니다. 만약 해당 항목이 안전하게 복제되었다면, 리더는 해당 항목을 상태머신에 반영하고 클라이언트에게 처리 결과를 반환합니다.
만약 팔로워가 충돌이 나거나 느리게 동작하는경우, 혹은 네트워크 패킷이 유실되는 경우 리더는 모든 팔로워가 모든 로그 항목을 저장할 때 까지 AppendEntries RPC를 무한히 재시도 합니다. (처리 결과가 클라이언트에 응답되었다고 하더라도)
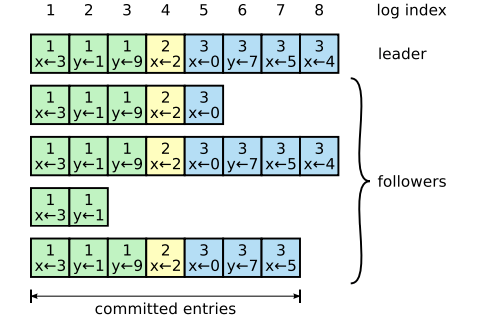
committed 라고 간주되는 항목들은 모든 상태머신에 반영되기에 안전한것들을 의미합니다. (정족수 이상의 서버들에 잘 복제되어있는 상태기 때문에)로그는 위 그림에서 보는 것 처럼 정리됩니다. 각 로그 항목은 리더로부터 전달받은 항목들을 상태머신의 command를 임기(term)숫자와 함께 저장합니다. 각 로그 항목은 로그안에서의 위치를 지정하기 위해서 정수형태의 index를 갖고 있습니다.
리더는 언제 로그 항목을 상태 머신에 반영해야 안전한지 결정합니다. 그런 로그 항목을 committed 되었다고 부르겠습니다. Raft는 커밋된 항목이 안정적이고, 결국에는 모든 가용한 상태 머신들에 의해 실행될 것임을 보장합니다.
로그 항목은 정족수 이상의 상태머신에 복제된 항목을 리더가 한번 커밋합니다. 이전 리더에 의해 생성된 항목을 포함하여 리더의 로그에 있는 모든 선행 항목도 모두 커밋합니다.
리더는 계속해서 커밋되어야할 가장 최신(높은)값의 index를 계속해서 추적합니다, 그리고 이 값은 AppendEntries RPC (hearthbeat 포함)내에 포함되어서 다른 서버들이 알 수 있게 합니다. 팔로워가 로그 항목이 커밋되었다는걸 알게 되면, 팔로워 자기 자신의 로컬 상태 머신에 해당 항목을 반영합니다. (순서대로)
Raft는 아래의 속성을 유지합니다.
- 만약 서로 다른 로그에서의 두개의 항목이 같은 index 와 같은 term 을 갖고있다면, 그것들은 같은 command를 저장합니다.
- 만약 서로 다른 로그에서의 두개의 항목이 같은 index와 term 을 갖고있다면, 그것들은 모든 선행 항목에서 동일합니다.
첫번째 속성은 리더가 주어진 로그 index와 term에서 오직 하나의 항목만 생성한다는 사실을 통해 이뤄지고, 로그 항목은 절대로 로그 안에서의 위치(index)를 바꾸지 않습니다.
두번째 속성은 AppendEntires RPC를 통해 이뤄지는 간단한 일관성 체크를 통해서 보장됩니다. AppendEntries RPC가 보내질 때, 리더는 새로운 항목들 바로 앞에 있는 자신의 로그 내 항목의 index와 term 을 포함시킵니다.
만약 팔로워가 같은 index와 term을 포함하는 해당 로그의 항목을 찾지 못하는 경우, 새로운 항목을 거부합니다.
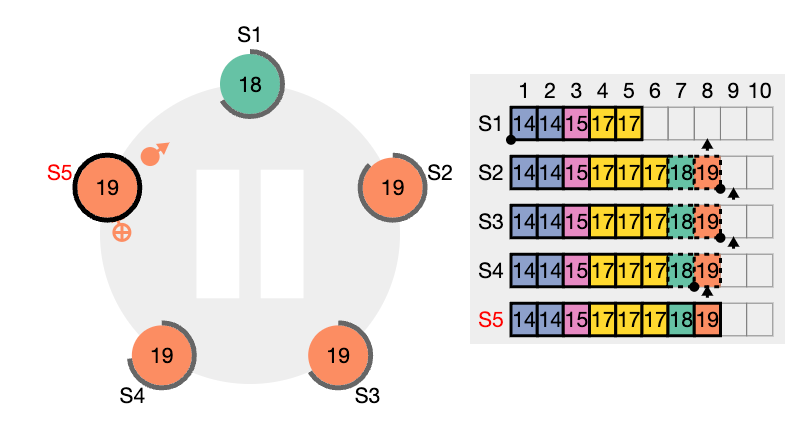
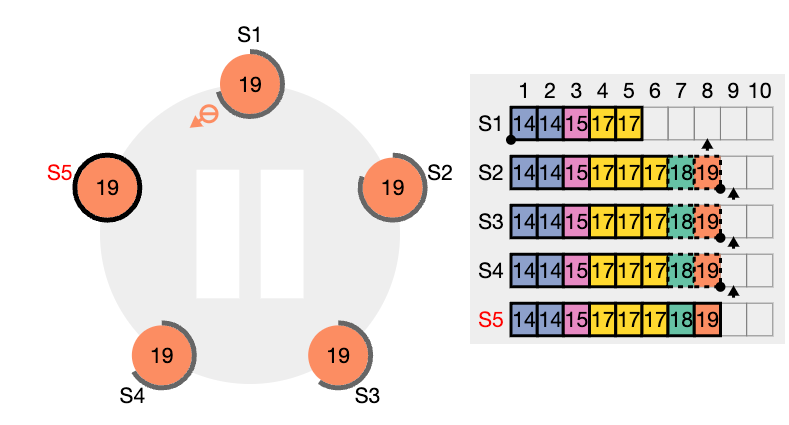
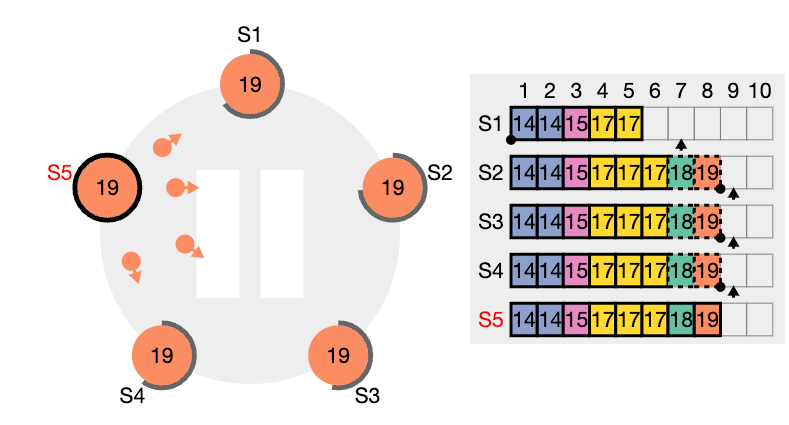
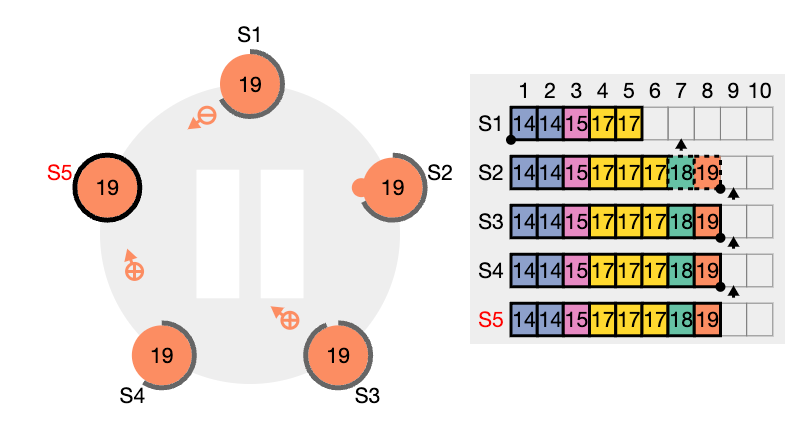
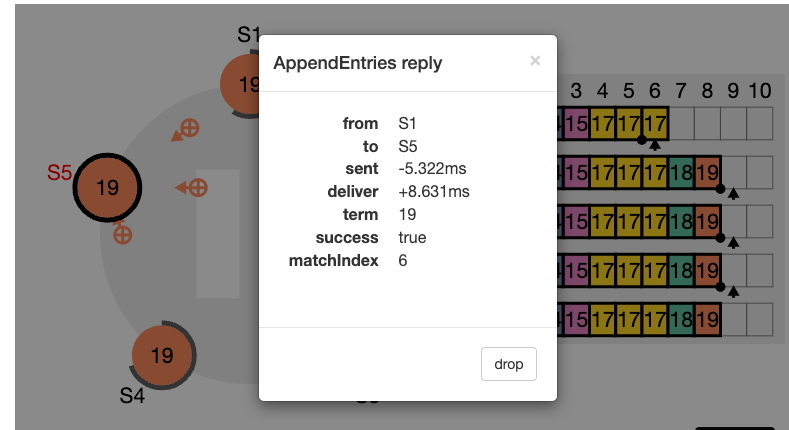
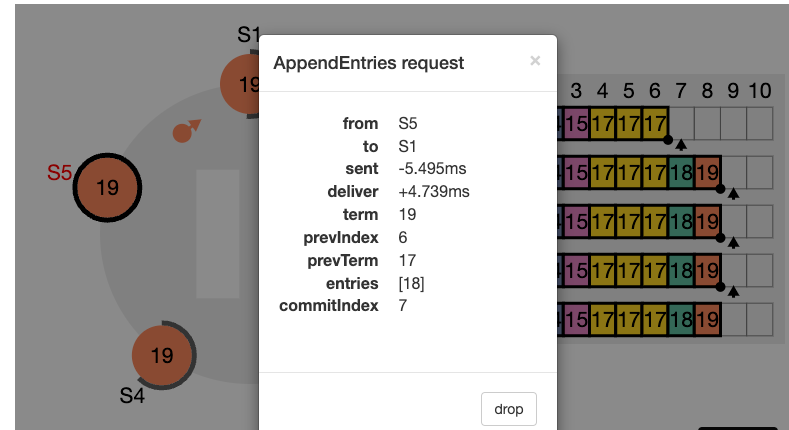
이런 일관성 검사는 귀납적으로 작용합니다. 로그의 초기 빈 상태는 로그 일치 속성을 만족시키고, 일관성 검사는 로그가 확장 될 때 마다 로그 일치 속성을 보존합니다. 그 결과로 AppendEntries 가 성공적으로 반환 될 때 마다 리더는 팔로워의 로그가 새 항목을 통해 자신의 로그와 동일하다는 것을 알게 됩니다.
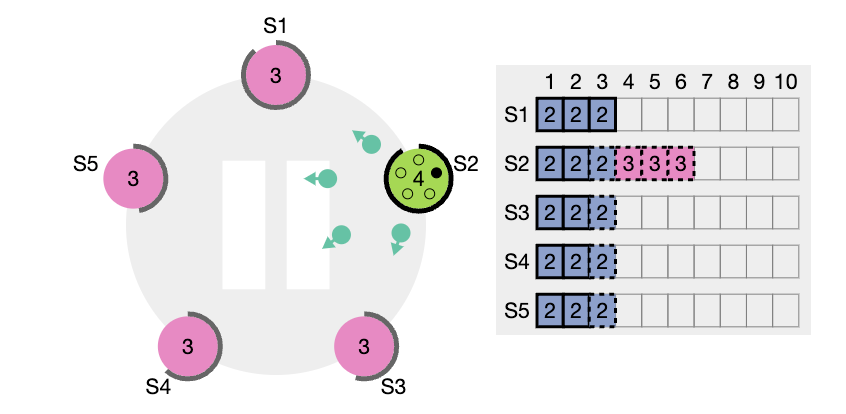
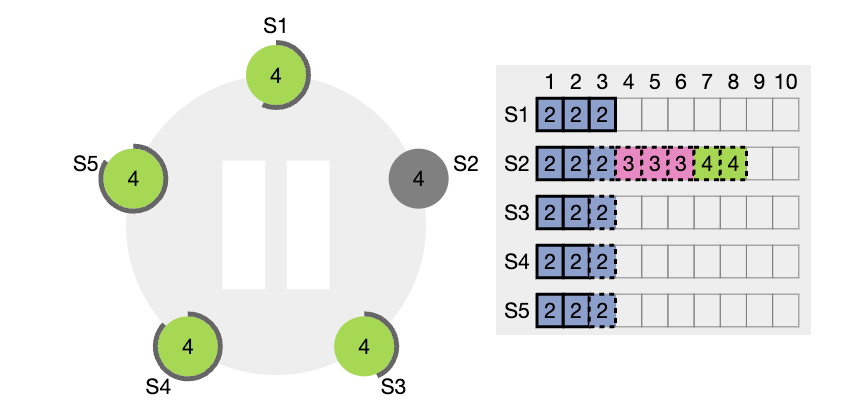
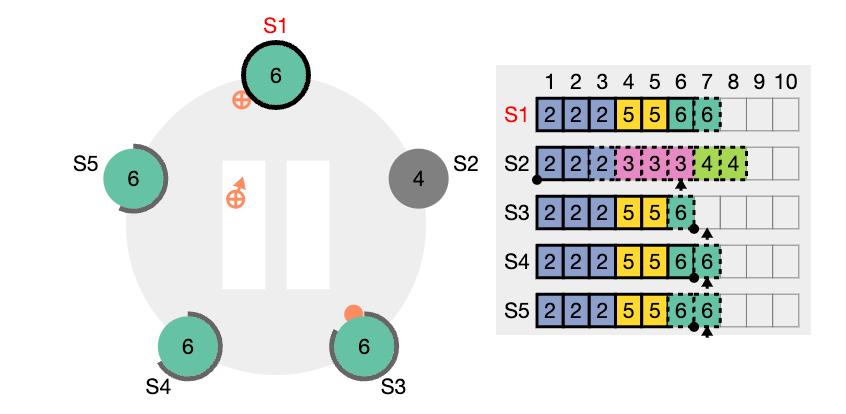
정상적인 운영 상황에서는 리더와 팔로워들의 로그가 일관성 있게 유지되므로, AppendEntries 의 일관성 체크는 절대로 실패하지 않습니다. 그러나 리더의 crash 는 로그 일관성을 깰 수 있습니다. (이전 리더가 자신의 로그에 있는 항목을 모두 복제 못했다면).
이런 비일관성은 여러차례의 리더와 팔로워의 crash 로 발생 될 수 있습니다. 팔로워는 리더에게는 있는데 자신에게 없는 항목을 누락 할 수도 있고, 리더에게 없는 추가 항목을 가질 수 도 있고, 둘다 그럴수도 있습니다. (위 그림들 참고)
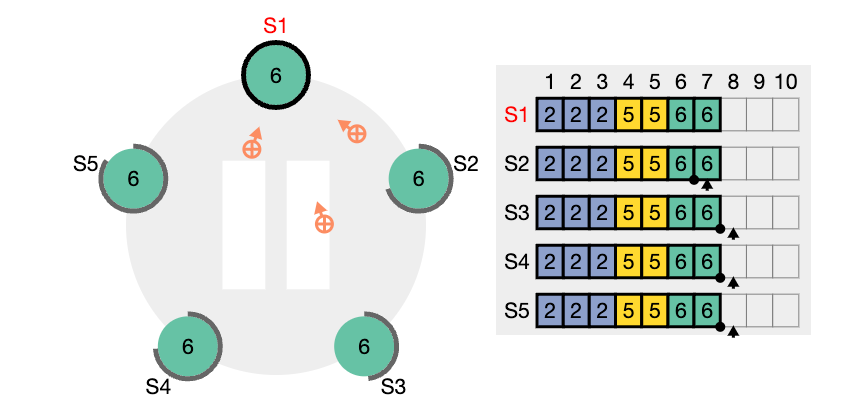
Raft 에서는 리더가 팔로워들의 로그를 자신의 로그를 복제하도록 강제함으로써 이런 일관성이 깨지는 문제를 처리합니다. 즉, 팔로워 로그의 충돌하는 항목들은 리더의 로그로 덮여쓰여진다는 것을 의미합니다.
팔로워의 로그를 리더의 로그와 일치시키기 위해서, 리더는 팔로워와 자신이 일치하는 가장 최근의 로그를 찾아야 합니다. 그리고 그 지점 이후의 팔로워의 로그의 모든 항목을 삭제하고, 팔로워에게 그 시점 이후의 모든 리더의 로그를 보내야 합니다.
이런 모든 일들은 AppendEntries RPC의 일관성 체크가 수행됨으로써 이루어 집니다.
리더는 각 팔로워의 nextIndex 를 관리합니다. 이 값은 팔로워에게 리더가 보내야하는 다음 로그 항목의 index 값을 의미합니다. 리더가 처음으로 본인의 임기가 시작되었을 때, 모든 팔로워의 nextIndex 값 (리더 내부적으로 관리하는 각 서버들에 대한 메타 데이터입니다.) 을 자신의 마직 로그 index의 다음 값으로 초기화 합니다.
만약 팔로워의 로그가 리더의 것과 일치하지 않는다면 AppendEntries RPC 에서의 일관성 체크가 실패할 것이고. 팔로워가 AppendEntries RPC 에 대한 응답을 거부하고, matchIndex 0 을 전달하면, 리더는 해당 팔로워의 nextIndex 값을 감소시키고 AppendEntries RPC 를 재시도 합니다. 이 과정이 반복되면 결국에 리더와 팔로워의 nextIndex 값이 일치하는 지점에 도달합니다.
결국 이렇게 nextIndex 값이 일치하는 지점에서 팔로워는 충돌되는 모든 해당 시점 이후의 로그를 제거하고, 리더의 로그에서 새로운 항목들을(있다면) 추가합니다.
이런 메커니즘을 통해 리더가 부임되었을 때 로그 일관성을 복원하기 위해 특별한 조치를 할 게 없습니다. AppendEntries의 일관성 검사의 실패가 누적되다 보면, 불일치 지점을 찾고, 복원하는 방향으로 로그들이 수렴됩니다.
리더는 절대로 자신의 로그에서 로그 항목을 덮어쓰거나 삭제하지 않습니다. 이러한 로그 복제 메커니즘은 서버의 정족수 이상이 작동중인 한 Raft 는 새로운 로그를 수락하고, 복제하며, 반영 할 수 있게 됩니다.
정상적인 클러스터는 정족수 이상의 서버에 단 한번의 RPC로 새 항목을 복제 할 수 있습니다. 또한 단 하나의 느린 팔로워가 성능에 영향을 미치지 않습니다. (리더는 정족수 이상의 서버에 로그가 복제되면 commit 하기 때문에 !!!)
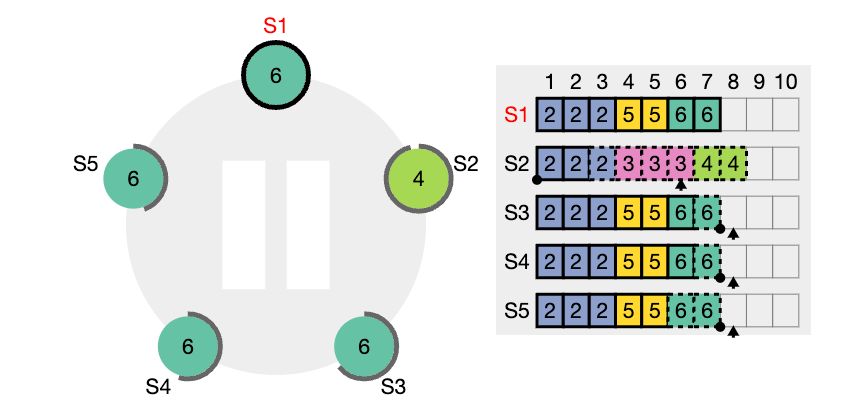
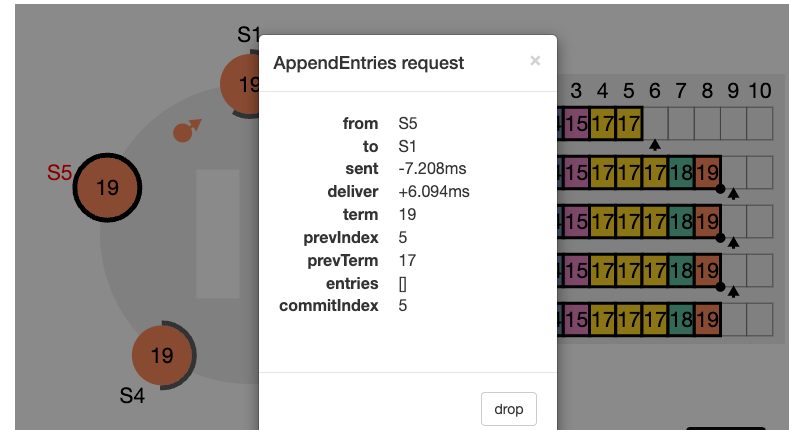
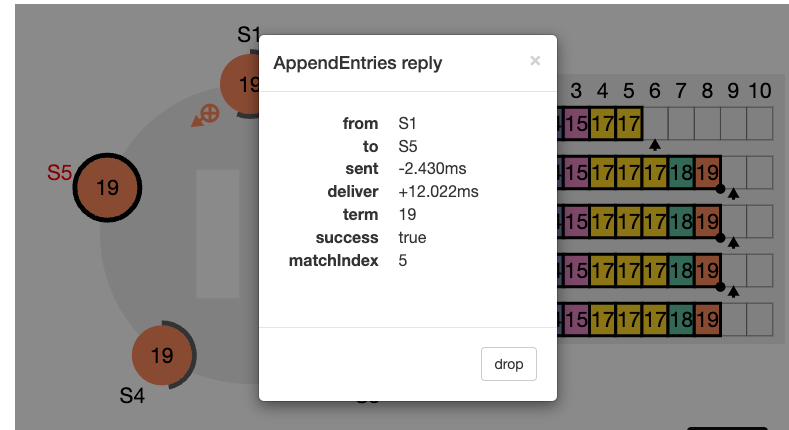
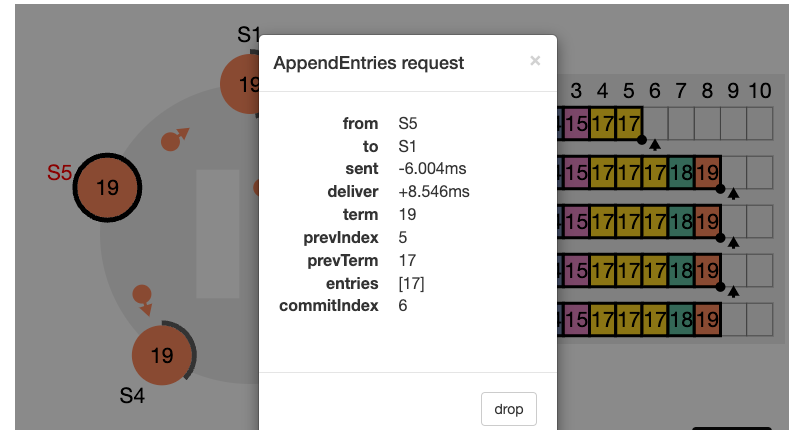
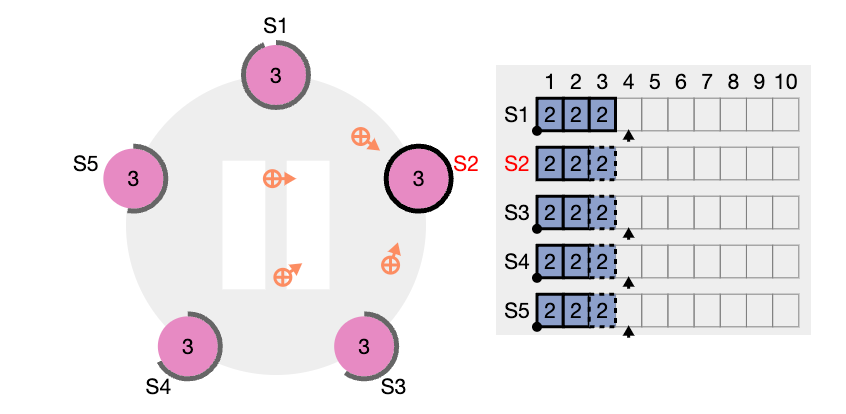
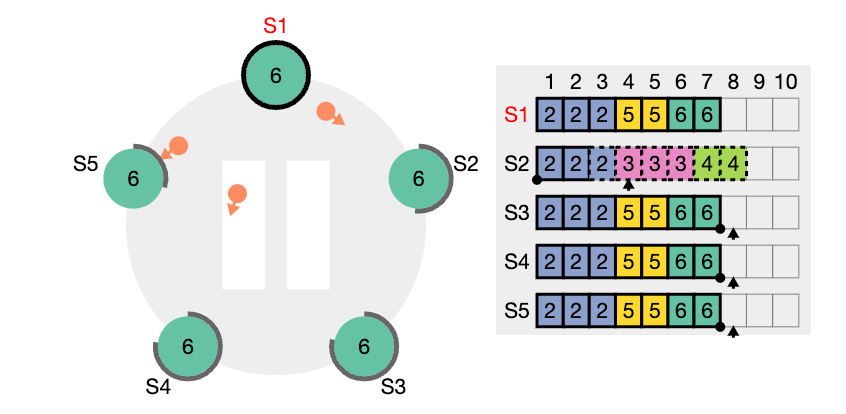
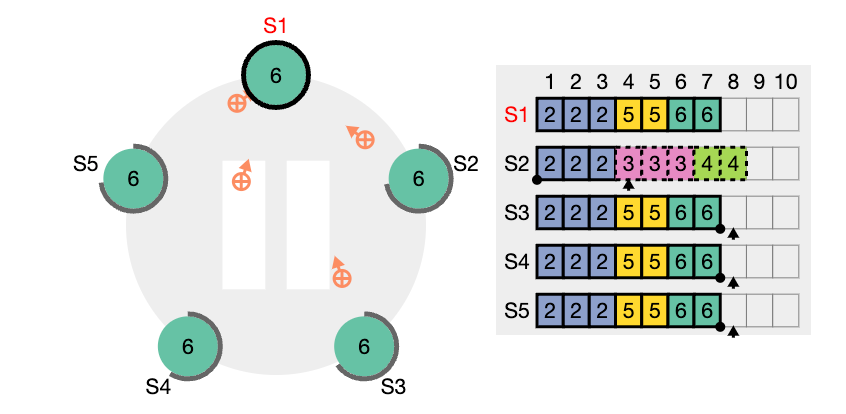
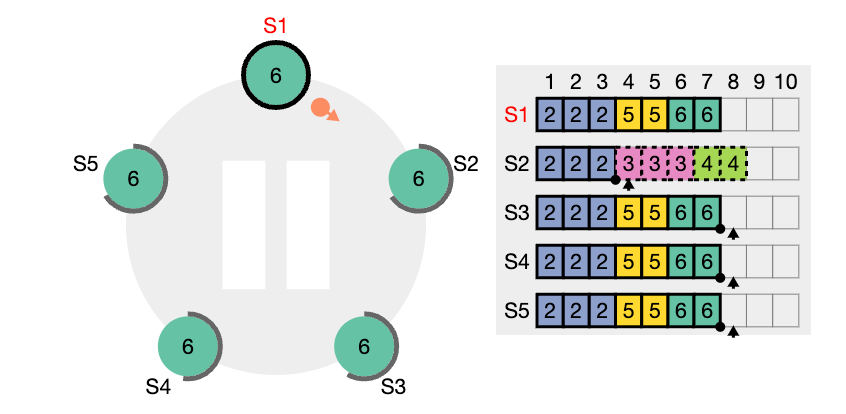
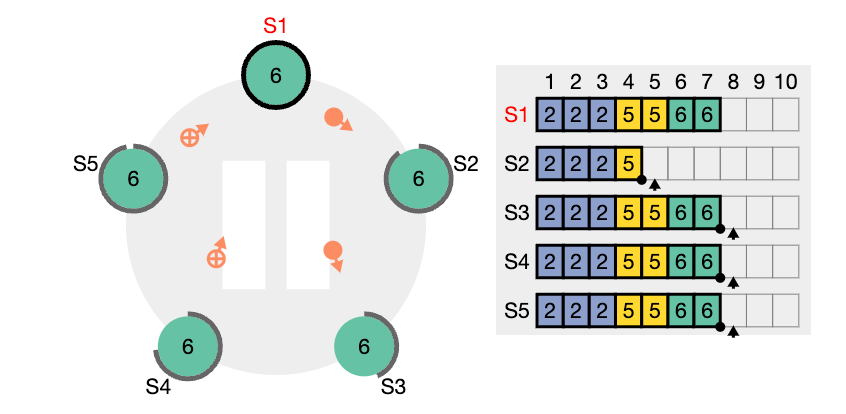
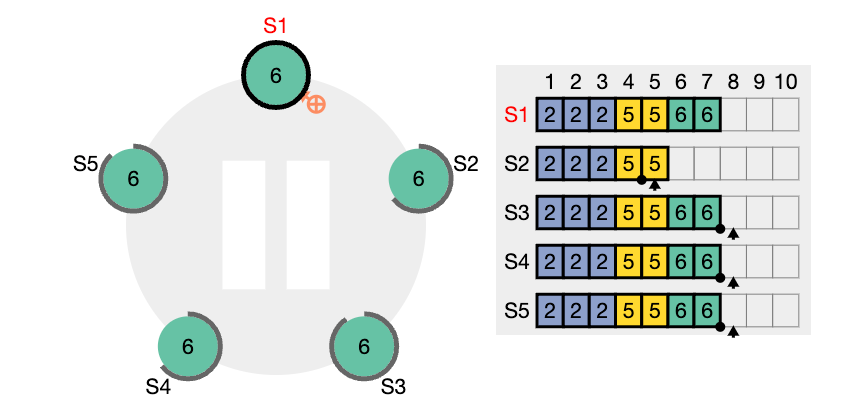
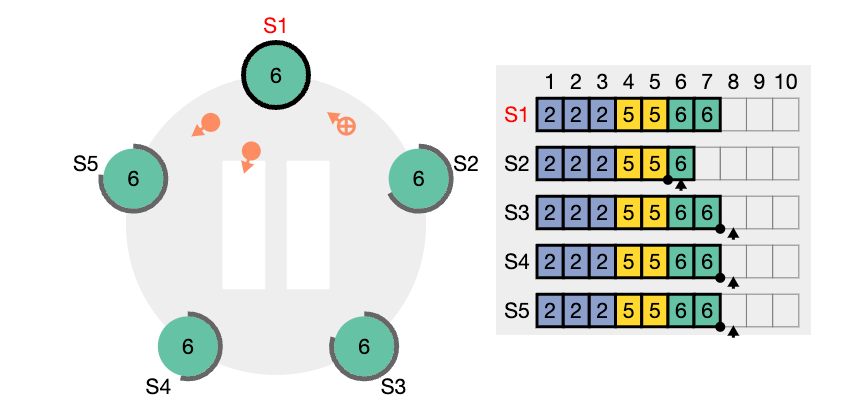
nextIndex 값을 의미한다. S2는 현재 nextIndex 값이 6 인 상태이다 (리더가 보기에) 또한 임기 값도 4이기 때문에 업데이트 되어야 한다.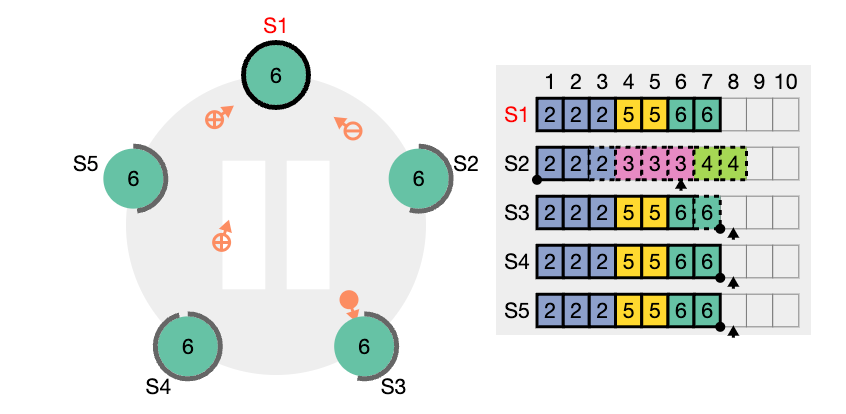
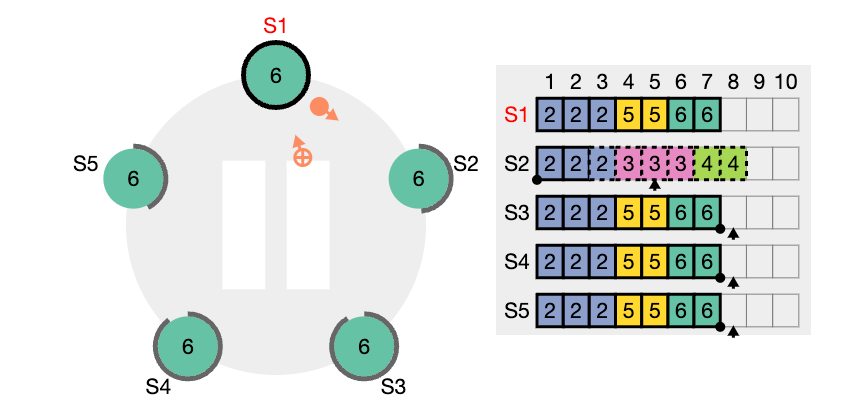
nextIndex 값은 5 라고 업데이트하고 (prevIndex4) 그리고 해당 인덱스에서의 로그 항목을 전달해서 일치하는지 체크해보려고 한다. (AppendEntries RPC)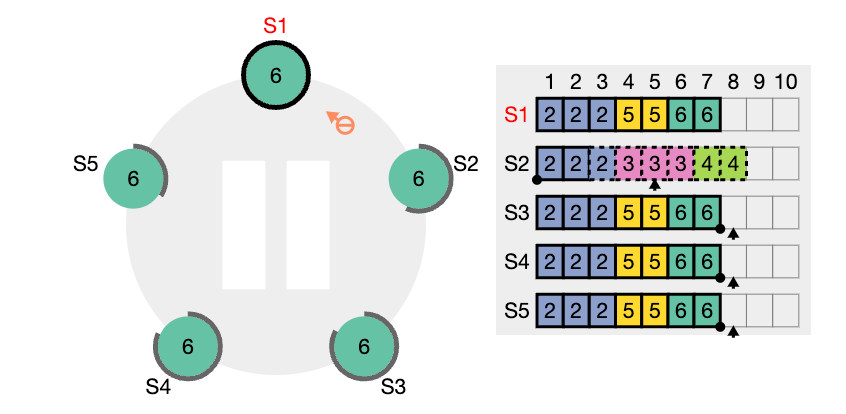
안정성
앞선 섹션들에서는 Raft가 어떻게 리더를 선출하고, 로그 항목을 복제하는지 설명했습니다. 그러나 지금까지 설명한 메커니즘만으로는 각 상태머신이 정확히 같은 command 들을 같은 순서로 실행한다는 것을 충분히 보장하진 못합니다.
예를들어서, 리더가 여러 로그 항목을 커밋하는 동안 팔로워가 사용 할 수 없게 되었다가, 그 후에 리더로 선출되어 이 항목을 새로운 것들로 덮어 쓸 수도 있습니다.
결과적으로 다른 상태머신들은 다른 시퀀스의 command를 수행하게 됩니다.
이제 부터는 리더로 선출 될 수 있는 서버에 대한 제한을 추가함으로써 Raft 알고리즘을 완성하는 내용을 설명합니다.
주어진 term 의 리더가 이전 term에서 커밋된 모든 항목을 포함하고 있음을 보장해야 한다는 제한을 추가합니다. 이러한 제한을 고려해서 커밋 규칙을 더 정확하게 만들어야 합니다.
선거 제한
리더 기반의 합의 알고리즘에서, 리더는 결국에는 모든 커밋된 로그의 항목을 반드시 저장하고 있어야 합니다. Viewstamped Replication 같은 일부 합의 알고리즘에서는, 모든 커밋된 항목을 갖고있지 않더라도 리더로 선출 될 수 있습니다.
이러한 알고리즘들은 선거 프로세스가 진행중이거나, 리더 선출 바로 직후에 누락된 항목을 파악하고, 새로운 리더에게 전달하는 추가적인 알고리즘을 포함하고 있습니다. 불행히도, 이런것들은 복잡한 알고리즘을 추가합니다.
Raft는 리더에게 커밋되었지만 누락된 항목을 새로운 리더에게 보낼 필요 없이, 이전 임기에서 커밋된 모든 로그 항목이 새로운 선거 시점에서 존재하는 리더만 선출하도록 보장하는 더 쉬운 접근법을 사용합니다.
이건, 로그 항목은 오직 한 방향으로, 리더에서 팔로워로만 흐르는것을 의미하고, 리더는 절대로 자신이 기존에 갖고있던 항목을 덮어쓰지 않는다는것을 의미합니다.
Raft는 모든 커밋된 로그 항목을 갖고있지 않은 후보자가 선거에서 이기는것을 막는 선거 프로세스를 사용합니다. 후보자는 반드시 클러스터 내의 과반수 이상과 통신하여서 뽑힙니다.
그 뜻은 모든 커밋된 항목은 반드시 연락했던 이 서버들중 최소한 하나에는 있다는 것입니다. (추가: 로그의 커밋은 과반수 이상의 클러스터 멤버에게 복제되었을 때 수행됨)
만약 후보자의 로그가 클러스터의 과반수 멤버들 중 어떤 로그보다 최신이라면, 그건 모든 커밋된 항목을 포함했다는 의미입니다. RequestVote RPC는 이러한 제한을 구현합니다.
RequestVote RPC 는 후보의 로그에 대한 정보를 포함하고, 투표자는 자신의 로그가 후보자의 것보다 더 최신이라면 해당 투표 요청을 거절합니다.
Raft는 두 로그 중 어느것이 더 최신인지를 로그의 마지막 항목의 인덱스와 임기를 비교해서 결정합니다. 만약 로그가 서로 다른 임기의 마지막 항목을 갖고있다면, 더 높은 숫자의 임기가 더 최신 로그입니다.
로그가 같은 임기로 끝나면, 더 긴 로그가 더 최신입니다. (같은 임기에 대한 로그가 더 많은쪽이 더 최신 로그까지 갖고 있는것)
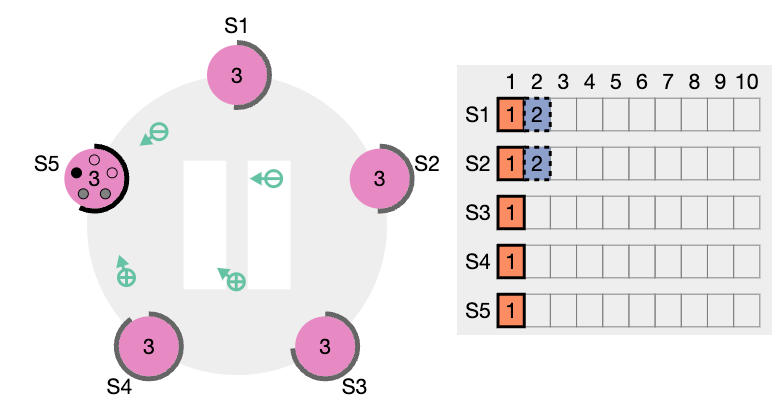
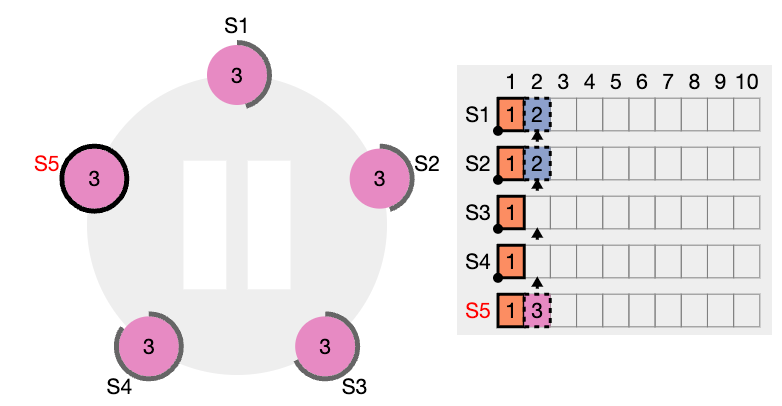
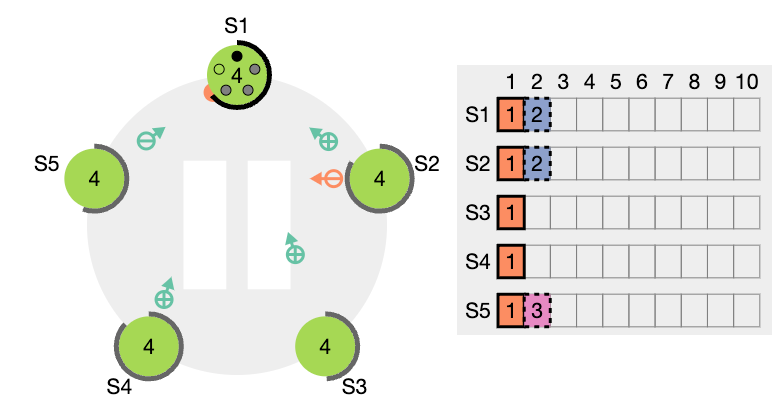
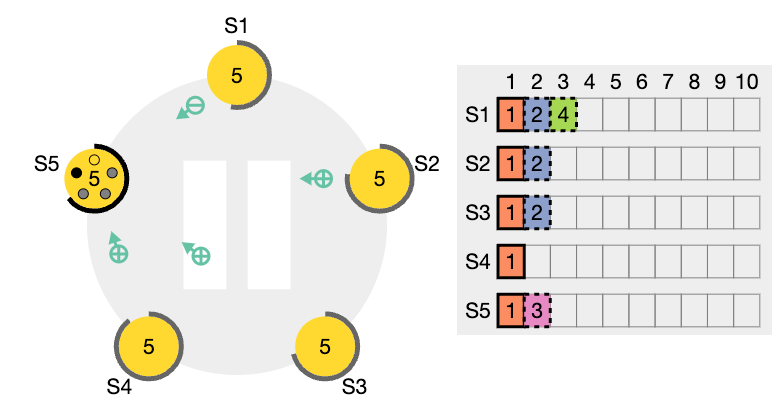
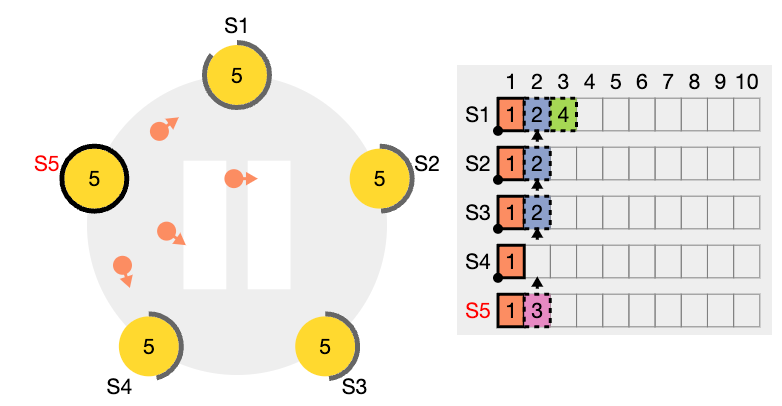
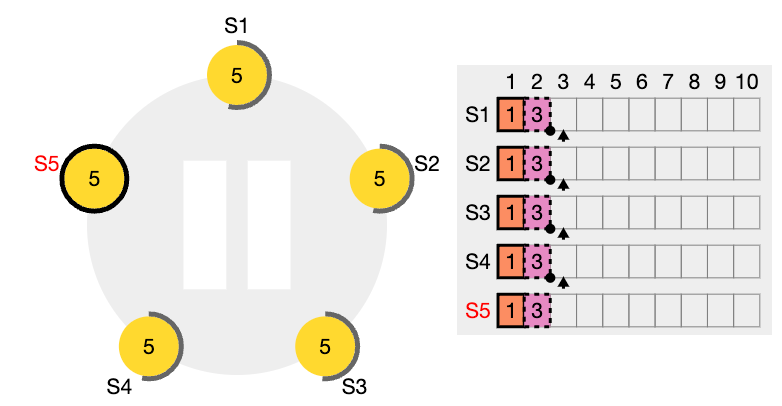
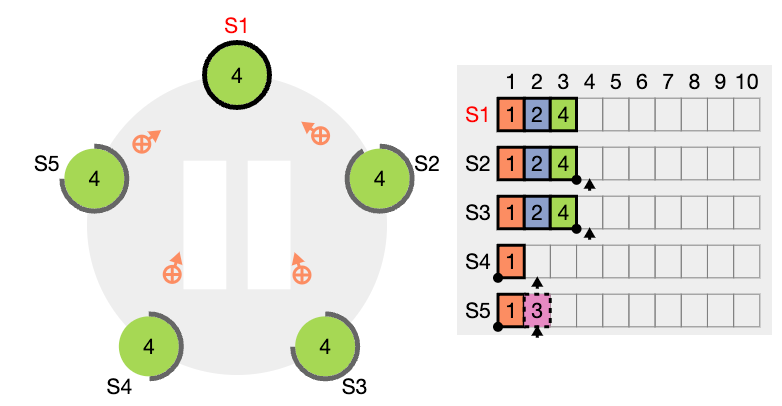
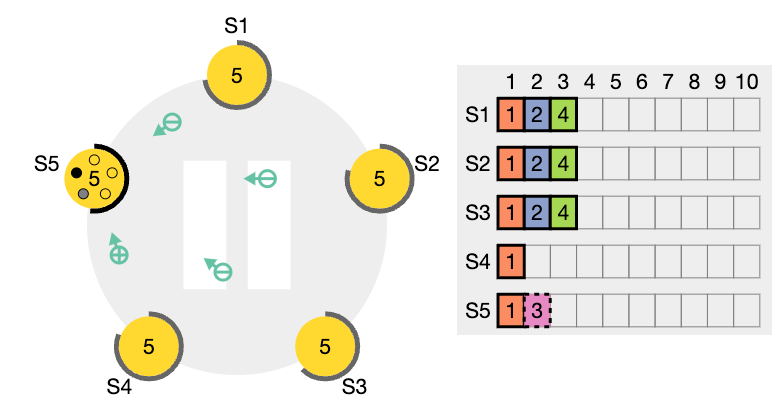
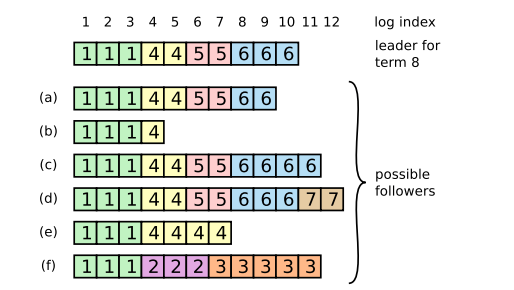
이전 임기의 항목들을 커밋
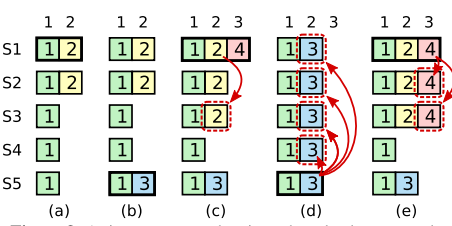
리더는 현재 임기의 항목이 서버 과반수에 저장되면 그 항목이 커밋되었다고 알고 있습니다. 리더가 항목을 커밋하기 전에 크래시가 발생하면, 미래의 리더들은 그 항목의 복제를 완료하려고 시도할 것입니다.
그러나, 리더는 항목이 서버 과반수에 저장되었다고 해서 곧바로 이전 임기의 항목이 커밋되었다고 결론지을 수 없습니다. 앞서 표현한 그림에서는 오래된 로그 항목이 서버 과반수에 저장되었지만, 여전히 미래의 리더에 의해 덮어쓰여질 수 있는 상황을 보여줍니다.
Raft는 이전 임기의 로그 항목을 복제 수를 계산하여 절대 커밋하지 않습니다. 오직 리더의 현재 임기에서 온 로그 항목만이 복제 수를 계산하여 커밋됩니다. 현재 임기에서 온 항목이 이런 식으로 커밋되면, 그 이전의 모든 항목들은 로그 일치 속성 때문에 간접적으로 커밋됩니다.
어떤 상황에서는 리더가 오래된 로그 항목이 커밋되었다고 안전하게 결론지을 수 있습니다(예를 들어, 그 항목이 모든 서버에 저장되어 있는 경우), 그러나 Raft는 단순함을 위해 보다 보수적인 접근 방식을 취합니다.
Raft는 커밋 규칙에서 이 추가적인 복잡성을 감수하는데, 이는 리더가 이전 임기의 항목들을 복제할 때, 로그 항목이 원래의 임기 번호를 유지하기 때문입니다.
Raft의 접근 방식은 로그 항목들이 시간이 지나도 같은 임기 번호를 유지하고 로그 전체에서 유지되기 때문에 로그 항목에 대해 추론하기가 더 쉽습니다.
또한, Raft의 새로운 리더들은 다른 알고리즘보다 이전 임기의 로그 항목들을 더 적게 보냅니다(다른 알고리즘은 커밋하기 전에 재번호를 매기기 위해 중복 로그 항목들을 보내야 합니다).
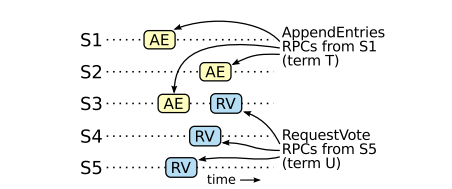
팔로워와 후보자의 충돌
지금까지는 리더의 실패에 대해서만 설명했는데, 팔로워와 후보자의 충돌은 더 처리하기 간단하고, 둘 다 같은 방식으로 처리 됩니다. 팔로워와 후보가 충돌한다면 그것들에게 보내진 미래의 RequestVote RPC , AppendEntires RPC 모두 실패 할 것입니다.
Raft 는 이러한 실패를 무한히 재시도 함으로써 처리합니다. 크래시한 서버가 재시작 되면 RPC 는 성공적으로 처리 될 것입니다. 예를들어 팔로워가 이미 자신의 로그에 존재하는 로그 항목을 포함하는 AppendEntries RPC 요청을 받는다면, 새 요청에서 그 항목을 무시합니다.
타이밍 그리고 가용성
Raft 의 요구사항중 하나는 타이밍에 의존해서는 안된다는 점입니다. 몇몇 이벤트가 예상보다 빠르거나, 느리게 처리된다고 해서 올바르지 않은 결과를 발생시키면 안됩니다.
어쨌든 가용성은 타이밍에 의존하게 될 수 밖에 없습니다. 예를 들어서, 메시지 교환이 일반적인 서버 크래시 시간보다 길게 걸린다면, 후보자는 선거에 이기기에 충분한 시간동안 유지되지 못 할 것입니다. (안정적인 리더 없이 Raft는 계속해서 진행 될 수 없음)
리더 선출은 Raft 에서 타이밍이 가장 중요한 부분인데. 시스템이 다음 요구사항을 만족하면 안정적인 리더를 선출하고 유지 할 수 있습니다.
broadcastTime << electionTimeout << MTBF
이 부등식에서 broadcastTime 은 서버가 클러스터 내의 모든 서버에게 병렬로 RPC 요청을 보내고, 그들의 응답을 받는데 걸리는 평균 시간입니다. 그리고 MTBF 는 단일 서버에 대한 평균 고장 사이 시간입니다.
정상적으로 동작하고 있다.
만약 RPC 레이턴시 (broadcastTime)을 election timeout 보다 크게 잡는다면 어떻게 될까요?
RPC 요청이 주고 받아지는 시간보다 각 서버의 electionTimeout이 더 크기 때문에 리더가 선출되기 전에 계속해서 timeout이 발생하고 리더가 선출되지 않는 상황이 발생합니다.
여기서 broadcastTime 과 MTBF 는 우리가 설정 할 수 있는 속성이 아닌, 시스템이 가진 기본 속성입니다. 우리는 electionTimeout 을 설정 할 수 있습니다.
일반적인 서버에 대한 MTBF(평균 고장 간 시간)은 몇달 이상이고, broadcastTime 은 환경에 따라 다르지만 몇ms 에서 길게는 수십 ms 일 것입니다. (만약 etcd 멤버가 대륙간으로 멀리 떨어져있다면 수백ms 가 넘을 수 있겠지만).
일반적인 상황에서는 electionTimeout 은 아마도 10ms ~ 500ms 사이가 될 가능성이 높습니다. 따라서 이 타이밍 요구사항을 만족하는것은 크게 어려운 일은 아닐 것입니다.
클러스터 멤버쉽 변경 (멤버 추가 / 제거)
지금까지 우리는 클러스터의 configuration (합의 알고리즘에 참여하고있는 서버의 집합)이 고정되어있다고 가정했습니다. 실무에서는, 설정을 변경 할는것이 종종 필요합니다. 예를 들어서 장애가 발생한 서버를 대체하기 위해서나, 합의 알고리즘에 참여하는 서버의 개수를 변경할 때 필요합니다.
이런 작업은 전체 클러스터를 오프라인으로 만들고, configuration(설정)을 업데이트하고, 전체 클러스터를 재시작하는 형태로도 동작 할 수 있겠지만, 이 과정에서 클러스터 전체를 사용 불가능한 시점이 발생하게 됩니다.
게다가 그런 작업에 수동 작업 절차가 있다면, 오퍼레이터(운영자)가 에러를 발생시킬 리스크를 높이게 됩니다. 이러한 문제를을 피하기 위해서, Raft 합의 알고리즘에 자동화된 설정 방식을 포함하기로 했습니다.
클러스터의 설정을 안전하게 변경하기 위해서는, 설정을 변경하는 시점에서 반드시 같은 임기에 두 리더가 선출되는 가능성이 없어야 합니다. 불행하게도, 과거 설정에서 새로운 설정으로 서버가 직접 설정을 바꾸는 접근법에서는 안전한 방법이 없습니다. 모든 서버를 원자적으로 전환 할 수 없기 때문에, 전환중에 클러스터는 두개의 독립적인 과반수로 분리될 수 있습니다.
안정성을 확보하기 위해서는 설정의 변경은 두단계 절차를 통한 접근법을 사용해야 합니다. 예를 들어서, 일부 시스템은 과거 설정을 사용하지 않기 위해 첫번째 절차 들어가고, 그 시스템은 클라이언트의 요청을 처리하지 못합니다. 이후에 두번째 절차에서는 새로운 설정을 활성화시킵니다.
Raft에서 클러스터는 공동 합의라고 부르는 전환 설정으로 전환합니다. 공동 합의가 커밋되면, 시스템은 새로운 설정으로 전환합니다. 공동 합의는 오래된 설정과 새 설정을 모두 결합합니다.
- 로그 항목은 두 설정의 모든 서버에 복제됩니다.
- 어느 설정의 서버든 리더가 될 수 있습니다.
- 합의(리더 선출 및 항목 커밋)는 과거 설정과 새로운 설정 모든 쪽에서 각각 과반수 이상의 합의가 필요합니다.
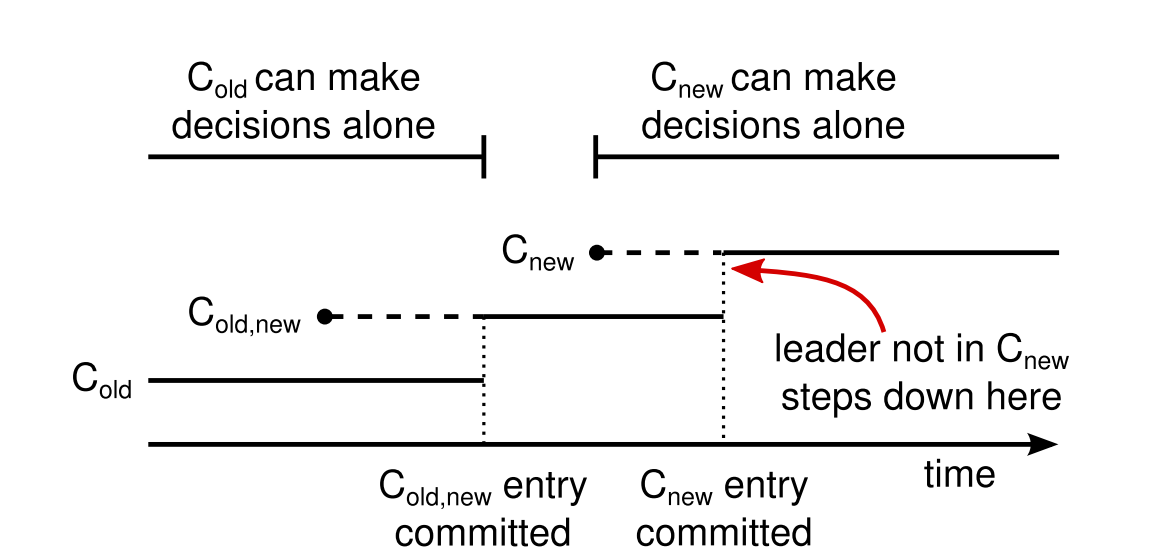
이러한 공동 합의는 각각의 서버들이 서로 다른 시간에 설정 전환을 할 수 있게 함으로써 안전성을 해치지 않습니다. 게다가, 공동 합의는 이런 설정이 전환되는 과정에서도 클라이언트 요청을 지속적으로 처리 할 수 있게 합니다.
클러스터 구성은 복제된 로그에 특별한 항목을 사용해서 저장되고 통신됩니다. 위 그림은 설정 변경 과정을 나타내는 그림입니다. 리더가 C_old 에서 C_new로 설정을 바꾸라는 요청을 받았을 때, 리더는 공동 합의를 위해 설정을 저장하고(C_old,new) 이 항목들을 복제합니다.
특정 서버가 자신의 로그에 새로운 설정 항목을 추가하면, 향후의 모든 결정에 대해 해당 설정을 사용합니다. (서버는 항상 로그에있는 최신 설정을 사용하고, 설정 정보가 커밋되었는지 여부에 상관없이 사용합니다.) 이는 리더가 C_old,new 규칙을 사용해서 언제 C_old,new 로그 항목이 커밋 될 지를 정한다는것을 의미합니다.
쉽게 정리하자면, 클러스터의 설정(구성) 정보가 변경 될 때, 구성 정보 변경하는 시점에서 일시적으로 분리(C_old,new)되는 클러스터가 독립적으로 각각 결정권을 갖는 시점이 없기 때문에 이 시점에서의 분리된(C_old,new) 클러스터간 데이터가 불일치하는 문제같은건 발생하지 않는다는 의미입니다.
로그 압축(Compaction)
Raft의 로그는 클라이언트의 요청이 포함된 정상적인 운영 상황에서 계속해서 늘어나게 됩니다.
하지만 실제 시스템에서는 경계(한계)없이 늘어날 수 없습니다. 로그가 더 길어지면 길어질수록, 더 많은 공간을 차지하게 되고, 응답을 하기위해 더 많은 시간을 사용하게 됩니다.
쓸모없는 정보가 로그에 계속 누적되었다는것을 인지하기 위한 메커니즘이 따로 없다면 결국 가용성 문제가 발생하게 됩니다.
Snapshotting(스냅샷)은 압축을 위한 가장 쉬운 방법입니다. 스냅샷을 찍게되면 현재의 모든 시스템의 상태가 안정적인 저장공간에 스냅샷 형태로 저장되고, 스냅샷을 찍는 시점 이전의 로그를 버립니다.
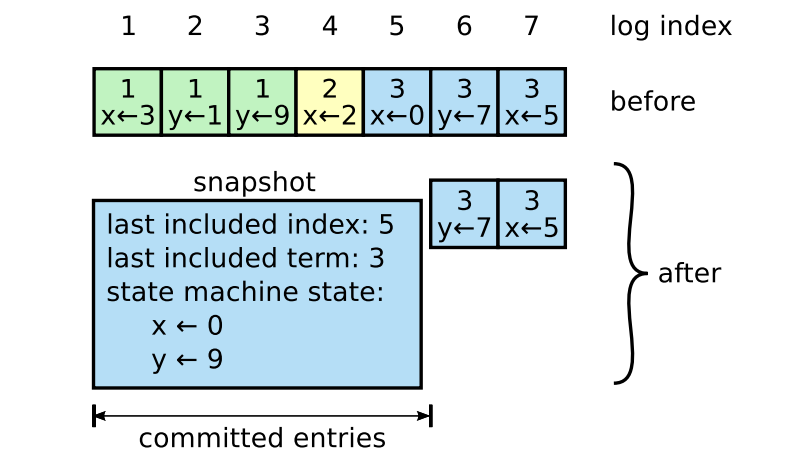
위 그림은 Raft 에서 스냅샷 생성의 기본 개념을 보여줍니다. 각 서버는 로그에 커밋된 항목들만 포함하여 독립적으로 스냅샷을 생성합니다. Raft 는 스냅샷에 소량의 메타데이터도 포함하는데, 스냅샷이 대체하는 로그의 마지막 항목의 인덱스, 그 항목의 임기(마지막 임기)를 포함합니다.
이 정보는 스냅샷 다음에 오는 첫번째 로그 항목에 대한 AppendEntries RPC의 일관성 검사를 지원하기 위해 보존되는 것입니다. 클러스터 멤버십 변경또한 지원하기 위해 마지막 서버 구성도 포함합니다. 스냅샷을 만들고 나면 그 이전 항목들을 삭제 할 수 있습니다.

리더는 InstallSnapshot RPC를 너무 멀리 뒤떨어진 팔로워들에게 스냅샷을 보내기 위해 요청합니다. 팔로워가 이 RPC 를 수신했을 때, 기존 로그 항목들을 어떻게 처리할지 결정해야 합니다. 보통은 팔로워가 갖고있는 로그 항목에 대한 정보보다 스냅샷에 있는 정보가 더 최신 정보입니다.
이런 케이스에서는 팔로워는 자신의 기존 로드 항목을 모두 버립니다. 만약 팔로워가 자신의 로그 항목의 앞부분을 설명하는 스냅샷을 받게 된다면 (재전송, 혹은 실수로 인해), 스냅샷으로 커버되는 앞선 로그항목은 삭제되더라도, 그 이후에 따르는 항목은 여전히 보존되어야 합니다.
이 스냅샷 접근 방식은 팔로워가 리더에 대한 정보 없이 스냅샷을 생성 할 수 있기 때문에 Raft 의 강한 리더 원칙을 벗어납니다.
하지만, 이러한 부분은 정당화가 된다고 생각합니다. 리더를 두는것은 합의에 도달할 때에 충돌하는 결정을 피하는데에 도움은 되지만, 스냅샷을 찍는 시점에서는 이미 합의가 된 상태기 때문에 어떤 결정도 충돌되지 않습니다. 데이터는 여전히 리더에서 팔로워로 한 방향으로만 흐릅니다.
etcd 의 --snapshot-count 는 compaction 수행 전에 in-memory 에 들고있을 Raft 로그 항목의 개수를 지정하는 옵션입니다. etcdctl backup 을 통해 만드는 snapshot 과는 별개의 개념입니다. Wrapping up
이렇게해서 Raft 알고리즘이 어떻게 동작하는지 논문을 기반으로 알아보았습니다.
이해하기 쉬우면서도(?) 잘 동작하는 합의 알고리즘을 구현하기 위해 어떤 요소들이 필요하고 일부 머신에 장애가 발생했을 때 어떻게 장애를 극복하는지 알아 볼 수 있었습니다.
위 사이트의 맨 아래쪽 부분에는 어떤 소프트웨어들이 Raft 알고리즘을 "구현" 하여 사용중인지 확인 가능합니다.